
Project Converse, generously funded by the Engelke Family Foundation, is dedicated to improving face-to-face expressive communication for individuals with complex communication needs (CCN) who use augmentative and alternative communication (AAC). Although AAC technologies have transformed access to communication, many individuals still encounter significant barriers when participating in one of the most fundamental human experiences: conversation.
Our mission was to challenge outdated assumptions about AAC-mediated communication and address the institutional barriers that have limited innovation in the field. Through a highly interdisciplinary approach, the project advanced research, design, and AAC technology development to better support real-world communication and human interaction.
Using a research-informed, interaction-centered approach, we designed and developed technologies that will support children learning AAC and help bridge the communication gap experienced by adults who rely on AAC. Our work is grounded in the belief that effective communication technologies must be shaped by the lived experiences of people who use AAC and informed by evidence from social interaction research.
This grant brought together researchers, engineers, designers, artists, clinicians, and people who use AAC to rethink how technology can support social engagement, mutual understanding, and personal agency. Rather than following a fixed roadmap, the project evolved through an iterative process in which each discovery informed the next phase of research, ultimately leading to targeted research programs and the development of AI-enhanced AAC technologies.
Core Values
Research Design Progression
Timeline
In 2016, augmented speaker Alan McGregor titled his ISAAC presentation, “No Further on After 30 Years, Still Can’t Speak Fast Enough.” His message was direct: despite decades of research and commercial development, AAC technologies still do not allow many people to participate easily in spoken conversation.
This remains the central problem Project Converse was designed to address. Speech-generating devices (SGDs) help people compose and speak messages, but they are still poorly suited to the timing, pace, and social demands of ordinary face-to-face interaction. Conversations move quickly. People respond, gesture, interrupt, repair misunderstandings, agree, disagree, and shift topics within seconds. For many augmented speakers, producing a message through a device takes so long that conversational moments pass them by. One augmented speaker described this problem clearly:
“In groups of people, I just couldn’t keep up with the conversation. By the time that I was finished typing, it was so far out of context that they would look at me as if I had three heads. This was discouraging to say the least.”
This is not simply a problem of slow typing. It is a problem of participation. When an augmented speaker’s contribution arrives too late, others may misinterpret it, not understand where it fits into the conversation, or may move on before it can be taken up. Over time, these delays can make the augmented speaker appear less competent, engaged, or socially present than they really are. As another augmented speaker put it:
“People assume that just because I have trouble communicating that I am slow or something. This frustrates me to no end.”
For adults who acquire communication disabilities after years of speaking, this loss can be particularly difficult. They understand both the consequences of slow composition and the importance of staying “in time” with conversational partners, but their technology may not allow them to keep pace. For children with complex communication needs, the problem begins even earlier. Many must learn to communicate through systems that do not match the fast, flexible speech of peers and adults around them, thereby limiting opportunities for friendship, play, learning, and social development.
The social cost is substantial. Augmented speakers often expend far more effort than their speaking partners to take part in conversation, and that effort can be exhausting. One augmented speaker explained:
“Sometimes I feel excluded from those around me because of the challenge to communicate at that particular time. Sometimes I feel people do not understand the extra time I take to communicate. I also use more energy to communicate, which gets tiring after a while. But communicating via Facebook and other social networking sites pales in comparison to interacting with real people.”
These experiences show why improving internet access, written communication, or the production of prepared messages is not enough. Augmented speakers need technologies that support the most basic and human form of communication: real-time conversation with other people.
Project Converse was created to take on this difficult problem. Our goal is to move beyond AAC systems designed mainly for writing and toward conversant AAC technologies designed around social interaction, timing, partner coordination, expressive speech, and the ability to participate in face-to-face conversation. This requires interdisciplinary, high-risk research that brings together augmented speakers, clinicians, engineers, social interaction scientists, computer scientists, designers, and manufacturers.
Our mission is clear: to develop research-informed AAC technologies that help children and adults not only produce messages, but participate more fully, more quickly, and more visibly in everyday conversation. Over the last 5 years, Project Converse has brought together a highly interdisciplinary research team to reinvent AAC for face-to-face conversation.
We have addressed this challenge in several ways:
- Investigating the interactional challenges experienced by individuals who use AAC during face-to-face communication, with particular attention to timing, partner coordination, repair, and participation in everyday conversation.
- Extending this work, through our partnership with UNC, to children and early AAC learning, recognizing that barriers to conversational participation begin early and shape later opportunities for social development, education, and peer relationships.
- Designing and developing conversant AAC technologies. AAC devices are intended not only to produce messages but also to help people actively engage in effective and efficient face-to-face interaction.
- Creating an interdisciplinary and inclusive research environment that brings together AAC users, clinicians, engineers, computer scientists, designers, and social interaction researchers. This includes creating roles and access for individuals who use AAC to contribute their ideas, experiences, and expertise directly to the development process.
- Finally, we use this research context to train the next generation of researchers, clinicians, and engineers by engaging students and colleagues in the interdisciplinary, high-risk innovation needed to move AAC beyond message production and toward fuller participation in conversation and community life.
Our work at the Communication and Assistive Device Lab (CADL) has been motivated by a core set of values that guide how we study, design, and evaluate AAC technologies:
- Sandbox mentality: We are a sandbox for discovery and design research, allowing us to move the field forward with multiple projects, including Enchrony, Move, Engage, Intone, culminating with Dynamic Expressive Augmented Narrator (DEAN). This approach enabled us to pivot as communication technologies evolved, especially with the rapid emergence of AI-AAC prototyping. That agility allowed us to explore new technical possibilities in real time while keeping the larger goal constant: developing technologies that help augmented speakers participate more fully in real-time conversation.
- Social interaction focused: We begin with the organization of real face-to-face interaction and design outward from there. Our goal is not only to improve message production but to develop AAC technologies that support timing, partner coordination, mutual understanding, expressive action, and social participation.
- User informed: Our research and research design work are grounded in the experiences and practices of augmented speakers. We draw on the AAC literature, video analyses of real AAC-mediated interaction, and the direct expertise of augmented speaker co-researchers to identify problems, evaluate our innovations, and guide the development of technologies that better support face-to-face conversation.
- Design research: We use prototype development to investigate AAC-mediated interaction. Rather than treating design as the final step after research, we iterate through interaction analysis, prototype development, user feedback, and field testing to determine which technologies best support face-to-face conversation.
- Show me: We ground our design decisions in observable evidence. Video analysis, transcription, prototype testing, and user feedback allow us to see how AAC technologies actually work in interaction and to revise our designs based on what participants do, not only on what we assume they need.
- Lab to table: We move research and prototypes from the lab into the everyday settings where AAC-mediated interaction occurs. By testing technologies with augmented speakers and partners in real conversational contexts, we evaluate whether our designs support participation beyond controlled laboratory conditions.
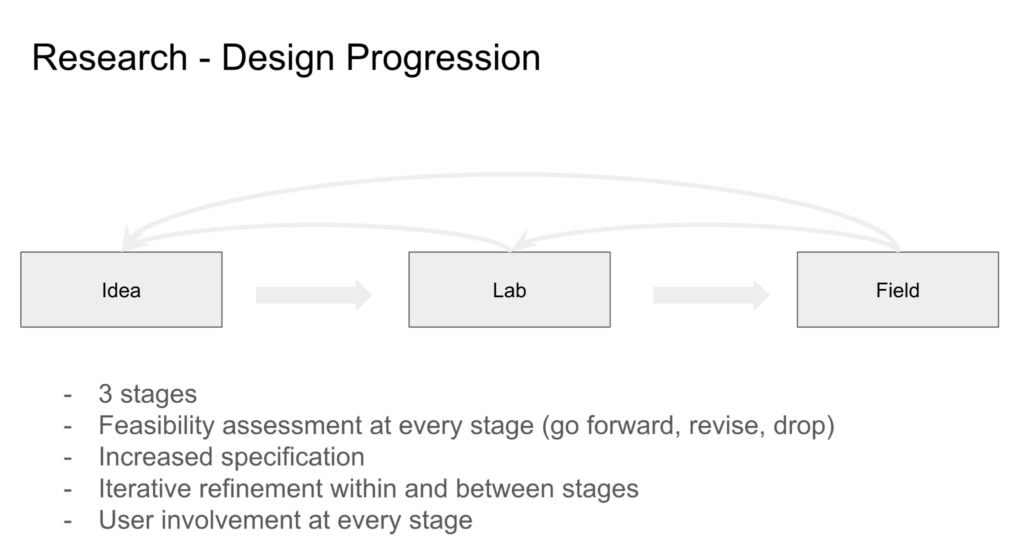
Our research-design process moves through three broad stages: Idea, Lab, and Field. We begin with an idea generated from interaction research, user experience, clinical observation, or a technical opportunity. That idea is then developed in the lab, where we build prototypes, test feasibility, refine methods, and examine whether the concept can be translated into a usable research tool. When a prototype is sufficiently developed, we move it into the field to study how it works in real interaction with augmented speakers and communication partners.
This process is not linear. At every stage, we assess feasibility and decide whether to move forward, revise the design, or drop the idea. As the work progresses, the design becomes more specified: broad concepts become prototypes, prototypes become testable systems, and testable systems become field tools. Findings from each stage feed back into earlier stages, allowing us to refine the idea, rebuild the prototype, or reconfigure the research question.
User involvement is central throughout the process. Augmented speakers, partners, clinicians, and project collaborators help us identify problems, evaluate prototypes, interpret findings, and determine whether a design has practical value. In this way, our work moves from idea to lab to field, but always through iterative cycles of evidence, feasibility testing, redesign, and user-informed refinement.
Year 2
Year 3
Year 4
Year 5
Summary
During the first year, much of the work focused on building the technical, personnel, and conceptual infrastructure needed to support this kind of research. We acquired and prepared laboratory space, purchased equipment and materials, developed the project website, wrote IRB protocols, hired and trained staff, and initiated transcription and video-analysis workflows.
This period also marked the formation of the core project team, including research staff and collaborators who would later lead work in interaction analysis, interface design, clinical research, speech synthesis, engineering, and conversational AI. At the same time, we began several exploratory lines of inquiry, including pragmatic interface design, eye-tracking methods, AAC engagement, speech output, interaction analysis, and early thinking about conversational AI.
These early strands were not yet tightly integrated, but they shared a common concern: current AAC technologies do not adequately support the timing, visibility, partner coordination, and social action demands of face-to-face conversation.
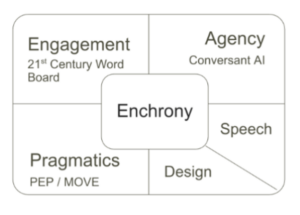
By the second year, these exploratory efforts had begun to take shape as distinct but connected research and development projects. Enchrony focused on identifying interaction problems, strategies, and design-relevant solutions in AAC-mediated conversation, with early emphasis on composition delay, repair, and grounded-unit analysis. This work was supported by the growing ELAN transcription database and by literature reviews that connected conversation analysis, AAC design, and pragmatic action. Move, initially developed as the Pragmatically Effective Phrase project, translated social-interaction research into an AAC interface built around pragmatically powerful words and phrases that could help users exert greater conversational control. Engage examined how AAC interfaces support shared attention and co-construction, while also advancing OS-DPI logging and analysis tools. Intone emerged from the recognition that conversationally appropriate synthetic speech would be essential for short, pragmatic AAC utterances. DEAN, then developing out of Project Agency, began as an effort to test conversational AI agents that could generate contextually responsive utterance options for augmented speakers.
Year 2 culminated in the 2023 Project Converse Workshop held in Buffalo, New York, which brought together an international, interdisciplinary group of researchers, clinicians, educators, designers, and technology developers to examine the future of AAC and communication technologies. Through presentations, demonstrations, discussions, and collaborative sessions, participants explored how emerging technologies can better support communication access, language learning, partner engagement, social participation, autonomy, and agency for individuals with complex communication needs. The workshop created a forum for sharing perspectives across communication sciences, human-computer interaction, education, accessibility research, artificial intelligence, and user-centered design, while identifying shared priorities for future research and innovation. A central outcome was the recognition that AAC technologies must be designed not only to support effective message production, but also to promote meaningful participation, quality of life, and full engagement in everyday social interaction.
Year 3 marked the midpoint of the project and a transition from capacity-building toward coordinated research and prototype development. Large-scale transcription began winding down as the team shifted toward accuracy checking and multi-participant analysis. By this point, we had developed a large video database for future research use, including more than 150 transcribed videos from 60 dyads involving adults with ALS, primary lateral sclerosis, cerebral palsy, and head injury. Grounded-unit analysis became a central method for segmenting AAC-mediated conversation into comparable stretches organized around the augmented speaker’s composition activity and the surrounding actions of both participants. The team also developed a continuous time-sampling technique that substantially reduced coding time for focused questions about interactional performance.
Enchrony provided the empirical and analytic foundation for this phase. Studies of composition delay, concurrent partner talk, repair, and intersubjectivity clarified how AAC-mediated interaction becomes vulnerable when message construction takes longer than the conversational moment allows. This work showed that delay is not simply slow message production; it can alter the sequential placement, intelligibility, and social uptake of an augmented speaker’s contribution. Repair studies further demonstrated that timely repair initiation was largely unavailable to many augmented speakers except through single selections, while graduate research projects provided empirical data on both other-initiated and self-initiated repair. These findings began to function as performance benchmarks for the design of future AAC systems.
At the same time, Move, Engage, and Intone matured as design-oriented research projects. Move advanced from paper-based interface design toward a digital OS-DPI implementation, supported by external modules, device-training resources, interaction-task catalogs, social-interaction training protocols, expressive speech work, and video analyses used to refine interface design. Engage tested interface configurations designed to support mutual gaze, shared attention, and partner access to message construction. Pilot results suggested that visual access to the AAC display supported more orderly and engaged interaction, leading to a larger study comparing multiple communication-mode conditions. Intone developed the expressive speech strand through collaboration with Eva Szekely at KTH Royal Institute of Technology, including recording and testing the Kaylie voice model, evaluating its feasibility through OS-DPI.
Year 3 also marked a major step in the emergence of DEAN as the project’s future integration point. The team installed a server for AI development and built a raspberry pi–based hardware/software architecture with cellular connectivity to manage input and output among the augmented speaker, partner, cloud-based ASR, language-model components, OS-DPI, and TTS. Todd Hutchinson continued as the first prototype evaluator and augmented speaker, and his 60-chapter memoir was used to train and personalize the language model. Initial LLM testing demonstrated both promise and limitation: the system could generate candidate responses, but a trained model alone was insufficient for producing relevant, contextualized, speaker-aligned utterances in conversation. This finding helped redirect the project toward a more layered account of AI-AAC development, in which infrastructure, language generation, interface design, timing, and social fit would all need to be developed together.
Year 4 became the project’s major integration year. Enchrony continued to provide the empirical foundation by documenting how composition delays create recurring problems in AAC-mediated conversation, including mishearings, misunderstandings, breakdowns in shared attention, and shifts in the sequential relevance of augmented-speaker contributions. Antara Satchidanand completed and defended her dissertation on other-initiated repair in SGD-mediated interaction, identifying significant asymmetries in repair initiation and repair types compared with typical spoken conversation. Gabrielle Martino completed and defended her master’s thesis on self-editing with SGDs, showing that users rely heavily on less efficient character deletion options during naturalistic interaction, even though simulation pointed to word deletion as more efficient. Work by Koroschetz, Possemato, and Higginbotham continued to examine concurrent partner talk during augmented-speaker composition as a major source of sequential misalignment affecting mutual understanding and social alignment.
Move and Engage reached major research milestones in Year 4. Move demonstrated that, after systematic training, an augmented speaker could use a Move-based AAC system to produce real-time turns with little or no temporal gap, including interruptions, insults, disagreements, repairs, and collaborative contributions. The project transitioned from a paper-based version to a dynamic OS-DPI interface, completed a replicated single-case pilot study, and prepared findings for publication. Engage documented engagement practices across AAC- and SGD-mediated interactions, using communication boards and natural speech as comparison points. Its results strongly favored shared visual access to the communication display, in sharp contrast to traditional SGD configurations that restrict partners’ access to message construction only. Together, Move and Engage showed that AAC design must support both rapid action by the augmented speaker and visible coordination with the partner during message construction.
Intone also reached an important decision point in Year 4. The collaboration with Eva Szekely produced valuable work on expressive speech synthesis, including experimental materials, a publication, and a conference presentation in Kyoto. However, the synthesis process proved difficult to control in real time for use with SGD. As a result, the team discontinued that line of interface development and shifted TTS work toward Microsoft Azure, which provided more practical control over prosody, loudness, and speech-act design for Move and DEAN.
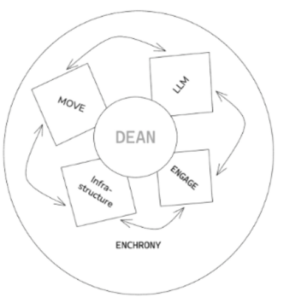
By the end of Year 4, DEAN had become the field-ready AI-AAC probe through which the project’s major strands were brought together. DEAN was organized as a layered system involving hardware and communications, language, social participation, and interface design. On the hardware side, we refined the communication architecture, migrated from Google Cloud to a UB server, integrated Hutchinson’s own device into the DEAN environment, and developed a remote observation and testing system. On the language and social side, we developed processes for conversational memory, personal information, history/persona modeling, and action-sequence prompting. From an interface perspective, we built and tested early interactive interfaces for Hutchinson and participants with ALS, integrating AI-generated responses, Move utterances, and tone-of-voice controls.
Testing during Year 4 clarified the limits of generic GPT-generated AAC responses. Hutchinson’s evaluations revealed major problems in interpretation, response generation, personalization, and speaker alignment. These findings showed that a fluent AI response is not necessarily an interactionally useful AAC response. The system needed to produce utterances that were timely, contextually relevant, personally acceptable, and aligned with the speaker’s stance and self-presentation. This work led to more fine-grained frameworks for assessing response quality and helped define the next phase of DEAN development. It also produced a major scholarly milestone: the team wrote and submitted a paper on conversational AI, AAC, and the early development and testing of DEAN, which was published in ATIA’s Assistive Technology Outcomes and Benefits in 2025.
Year 5 focused on refining and field testing DEAN with two augmented speakers who represented different interaction ecologies: Todd, a lifelong direct-select MinSpeak communicator with cerebral palsy, and Linda, an oral speaker prior to ALS who has used eye-tracking access with a Dynavox SGD for the past 12 years. This comparison allowed us to examine DEAN not as a single interface, but as an adaptable AI-AAC system that had to be customized for different bodies, devices, access methods, communication histories, and timing constraints.
Major technical progress occurred in DEAN’s hardware and communication layer. We reduced LLM response delays from approximately 10 seconds in 2023 to about 1 second, substantially improving the system’s potential to support near-time conversational participation. We also integrated a web-based version of DEAN directly into the communication devices our participants use daily, eliminating the additional hardware previously required for testing. This shift made DEAN more practical for field use and allowed the project to focus more directly on interactional performance rather than system assembly.
Year 5 also brought advances in DEAN’s language, interaction, interface, and speech-output layers. We integrated RAG-based memory, persona information, and action-sequence prompting to improve the relevance, continuity, and speaker alignment of AI-generated utterances. We combined AI-generated responses with Move-based pragmatic utterances, creating a hybrid system that supported both context-specific response generation and rapid conversational action. Each participant’s interface was customized to their access needs, and we began using ElevenLabs speech synthesis to provide more flexible, conversationally responsive speech output during testing.
Field testing became the central activity of the final grant year. We designed and implemented a multi-session Move training program for each participant, with the number of sessions adjusted according to each person’s improvement in selection accuracy and speed relative to baseline. We then designed a 10-session conversation field-test protocol with two tasks per session to compare each participant’s use of the DEAN conversational probe with their everyday AAC system. User training and testing began in February 2026 and were completed in May 2026. These field trials allowed us to evaluate DEAN under real interactional conditions, including timing, access demands, utterance selection, partner engagement, speech output, and the fit between generated responses and each participant’s communication style.
Across Year 5, Project Converse also moved decisively into scholarly dissemination. We devoted substantial effort to analyzing data and preparing manuscripts across the project’s major strands. During the year, we published three papers, had two manuscripts under review, and prepared three additional manuscripts for submission. We also gave nine presentations at national and international conferences, including five national and four international presentations. Higginbotham delivered two keynote addresses at an international conference, with two additional presentations planned for Fall 2026.
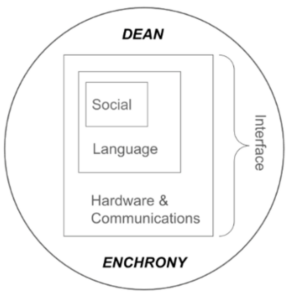
Over the course of the grant, Project Converse evolved from a set of exploratory sandbox projects into an integrated research program centered on DEAN. Enchrony provided the temporal and sequential foundation; Move provided rapid pragmatic action; Engage showed the importance of partner visibility and shared attention; Intone addressed expressive speech and prosody; and DEAN brought these strands together in a layered AI-AAC probe.
The project’s central contribution is not simply the development of a new prototype, but the creation of a research framework for designing and evaluating AAC technologies as tools for real-time social interaction. Project Converse has shown that the future of AAC innovation depends on more than faster typing, better prediction, or more fluent text generation. It requires technologies that help augmented speakers remain in time, in control, visible to their partners, and recognizably themselves within face-to-face conversation.