Intone
Engage
Move
Bridging Learning


Co-Directors: Higginbotham & Possemato
Associate Researchers: Koroschetz, Satchidanand, Project OPEN Collaborators
Start Date: October 2021
Our interaction research has shown that although augmented speakers communicate at varying rates, delays in message composition consistently create challenges during conversation. These delays can lead to mishearings, misunderstandings, disruptions in shared attention, and breakdowns in mutual understanding.
Many of these difficulties stem from the time required to compose linguistic messages using AAC systems. Communication delays place significant demands on attention and can disrupt the expected timing and flow of everyday interaction. For example, our research has shown that when communication partners speak simultaneously, the relevance and interpretation of an augmented speaker’s contribution can shift or become disrupted.
Our work has also examined how individuals using AAC navigate conversational repair, including both self-initiated repair and repair prompted by others. This research has identified important differences between spoken interaction and AAC-mediated interaction, particularly regarding the effort and time required to clarify misunderstandings and repair communication breakdowns.
Together, these findings provide an empirical foundation for evaluating and guiding our recent AI-AAC design efforts. They also establish measurable interaction benchmarks that can help assess whether emerging communication technologies meaningfully improve conversational participation and understanding.
Research Progress
Studies
Summary
“I found not having a real-time voice was the equivalent to not having any defense to what was done to my body…”
(Robillard, A. B. (1994). Communication problems in the intensive care unit. Qualitative Sociology, 17(4), 383–395.)

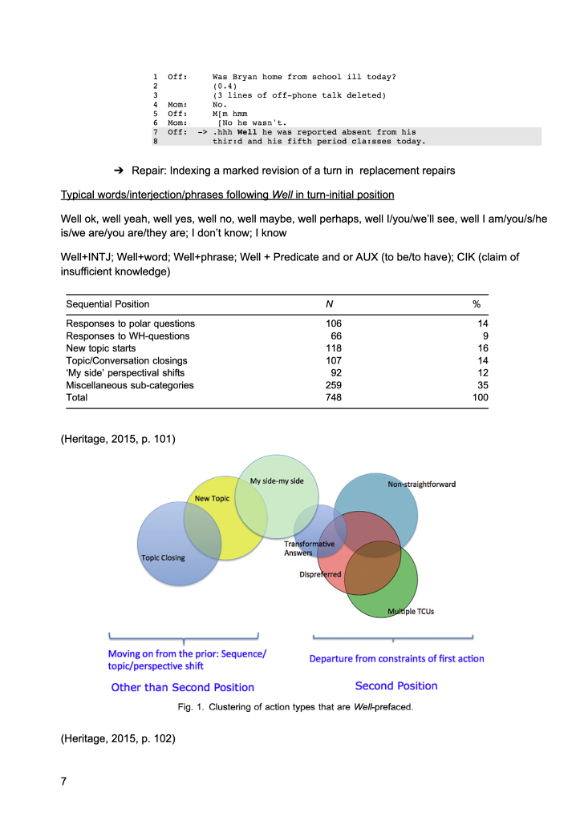
Enchrony refers to the moment-by-moment temporal organization of social interaction: the way actions are sequentially organized in-time so that each action responds to what just happened and shapes what is expected next. For Project Enchrony, this temporal-sequential organization provides the central frame for understanding AAC-mediated interaction:
- Conversation happens within an enchronic frame.
- Conversation carries a temporal imperative to keep interaction moving forward, a feature conversation analysts often describe as progressivity.
- Participants ordinarily work within a rolling “now” of roughly two to two-and-a-half seconds, where actions are still treated as connected to the immediately prior action.
- This enchronic window is a primary basis for organizing social interaction and has direct implications for participation in conversation, learning, work, and everyday social life.
Robillard’s work provides an important starting point for this project. Typical conversation is cooperative: we talk with each other in time, producing an orderly rhythm of coordinated action and speech. Robillard (1994) argues that this rhythm assumes the intersubjective coordination of physical bodies, making impaired access to conversational timing a breach of the normal conversational order that can leave the speaker vulnerable to misunderstanding, ignoring, or being treated as disruptive.
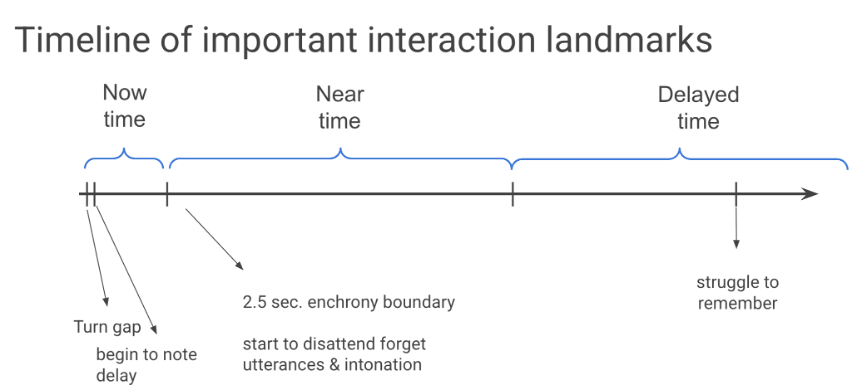
This figure illustrates the temporal frame through which conversational actions are understood:
- Now time: the immediate space in which turn transitions and responses are expected.
- Near time: the rolling enchronic window in which actions are still treated as connected to what just occurred.
- Delayed time: the point at which responses become harder to link to the prior action and more vulnerable to misunderstanding, disattention, overlap, repair, or loss of sequential fit.
- AAC composition delay: AAC composition delay is the time between an augmented speaker’s decision to compose an utterance and the moment that the utterance becomes available to the partner through visual display or speech output. This delay can affect overall communication speed, as well as the utterance’s sequential relevance and social uptake in conversation.
Project Enchrony grew out of CADL’s long-standing concern with the temporal-sequential organization of AAC-mediated interaction. The project focuses on how participants respond to temporally delayed talk, including the adjustments they make, the problems that result, and the ways AAC technologies reshape the timing of ordinary conversation.
Through collaboration with Project OPEN and prior CADL research, we developed a large video database of social interactions involving individuals with ALS, cerebral palsy, and other disabilities as they interact with others using their communication devices.
The central problem addressed by Project Enchrony is that AAC-mediated conversation is not delayed only in a mechanical or rate-based sense. Composition delay alters the temporal relationship between actions. A contribution that was sequentially relevant when the augmented speaker began composing may become misaligned, redundant, or difficult to interpret by the time it is produced. This makes enchrony a key analytic frame for understanding why otherwise appropriate and intelligible AAC utterances can become interactionally problematic.
Building the Data Infrastructure
Years 1 and 2 were devoted to developing a transcription protocol, establishing a pool of student transcribers, and training them to transcribe embodied and technologically mediated interaction between augmented speakers and their conversational partners. This training focused on treating participants’ bodies as interactional resources while also documenting how AAC devices shape the organization of conversation. Most participants were recruited through Project OPEN.
We collected video data by traveling to the homes of augmented speakers and their partners, including parents, spouses, children, and friends. Participants were recorded while engaging in a series of conversation tasks, such as video-sequence sorting, map reading, and shared-experience conversations. To date, most of our analytic work has focused on the shared-experience conversations.
Multimodal Transcription and ELAN
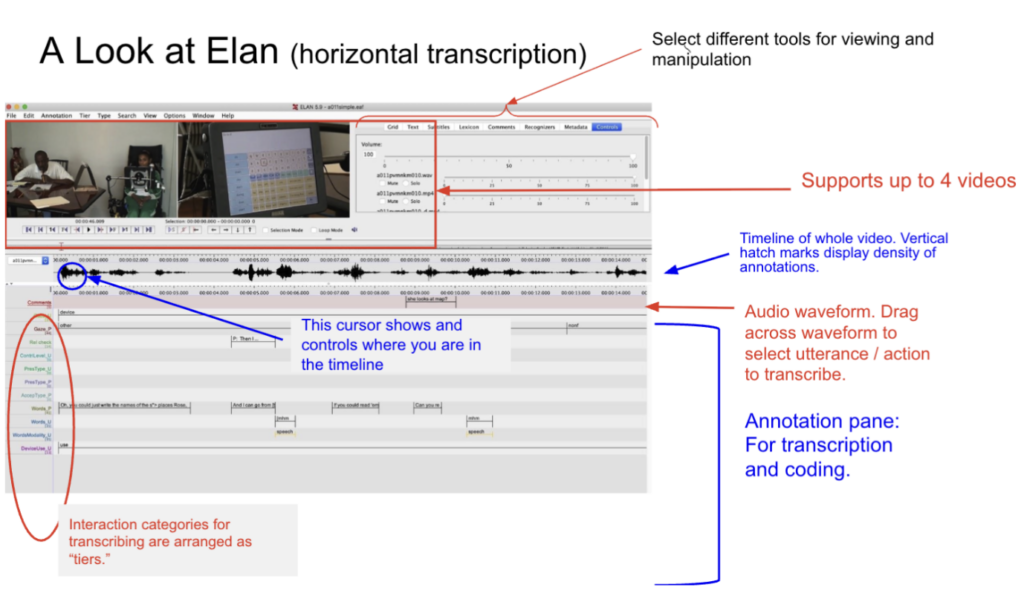
Our transcription process uses the EUDICO Linguistic Annotator, or ELAN, to produce detailed embodied transcripts of AAC-mediated interactions. ELAN allows us to create multimodal transcripts that capture speech, gaze, gesture, device activity, and speech output as they unfold between the augmented speaker and their conversational partner.
This transcription approach was essential because the phenomena of interest were not located in speech alone. Composition time, concurrent talk, repair, gaze shifts, device selections, and speech output all had to be examined as temporally coordinated parts of the same interactional ecology. The ELAN-based workflow therefore, became a methodological foundation for studying the relationship between device-mediated message production and the unfolding organization of talk-in-interaction.
Identifying the Problem of Composition Delay
During the second year, we began to identify recurring problems experienced by augmented speakers and their partners during interaction. One important case involved Ann and Bill discussing their honeymoon. During the conversation, Ann and Bill overlapped each other while talking, resulting in a complete misunderstanding by Bill. The case was especially striking because Ann typed at approximately 25 words per minute, which is extremely fast for someone using AAC. We did not expect to find this level of interactional trouble at such a comparatively fast AAC rate.

This case spurred a larger investigation of composition delay involving eight individuals with ALS and their partners. We used both quantitative descriptive methods to characterize aggregate patterns and detailed multimodal microanalytic techniques to examine how these problems emerged in interaction.
Grounded Unit Analysis
A major methodological contribution of Project Enchrony was the development of grounded unit analysis. During early work on composition delay, it became clear that we needed a way to segment conversation into interactional units that were comparable across participants, access methods, and conversations.
A grounded unit is organized around the augmented speaker’s composition activity. It includes the contribution before the augmented speaker’s turn that makes their utterance relevant, the augmented speaker’s whole composition process, actions by either participant during composition, the eventual AAC output, and the partner’s response. This unit allows us to analyze AAC-mediated interaction as a temporally organized sequence rather than as isolated device output.
We have applied grounded unit coding to approximately 20 conversations and plan to use this code in current and future studies. This approach is especially well-suited to SGD users who compose and issue utterances “in-the-whole,” but it can also be extended to more diverse utterance-production strategies, including communication-board interaction and mixed spoken/spelled production.
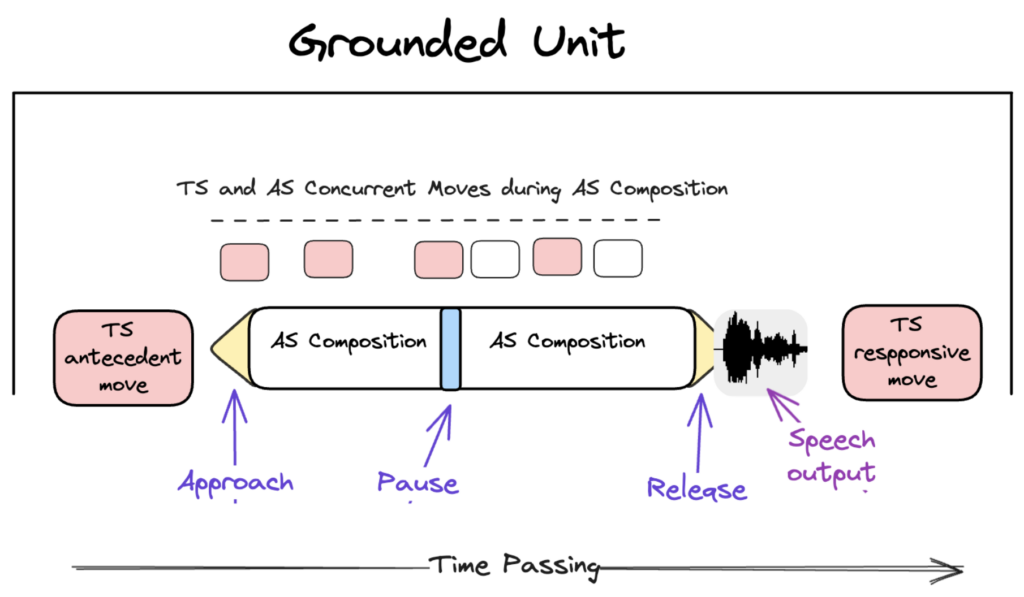
We have been using the grounded unit concept for our work on composition delay and an ongoing project in Project Open focusing on the impact of concurrent talk (i.e., partner talk that occurs during the augmented speaker’s ongoing compositions).
Analysis of Composition Delay
In collaboration with Project OPEN, our work on composition delay focused on understanding the talk-in-interaction dynamics that occur during augmentative message composition and the problems in intersubjectivity that arise during this process. This research also helped establish an empirical foundation for future AAC talk-in-interaction analysis by clarifying key concepts, terminology, and analytic techniques.
We studied the interactions of eight individuals with ALS and their partners while they discussed shared experiences. This analysis identified 91 grounded units for study. The participants varied substantially in access method, diagnosis, composition rate, and duration of composition activity.
We identified two groups of fast and slow communicators based on access method and diagnosis. Two-handed typists composed approximately four to five times faster than participants using switch access, eye tracking, head tracking, or other slower access methods. However, even relatively fast AAC composition frequently extended beyond the ordinary enchronic window of conversation.
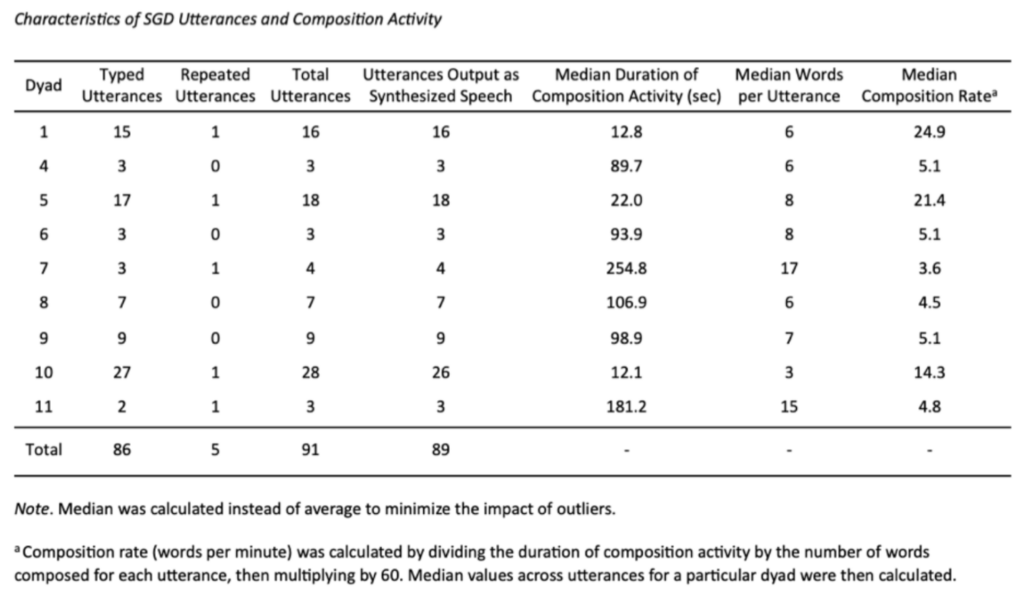
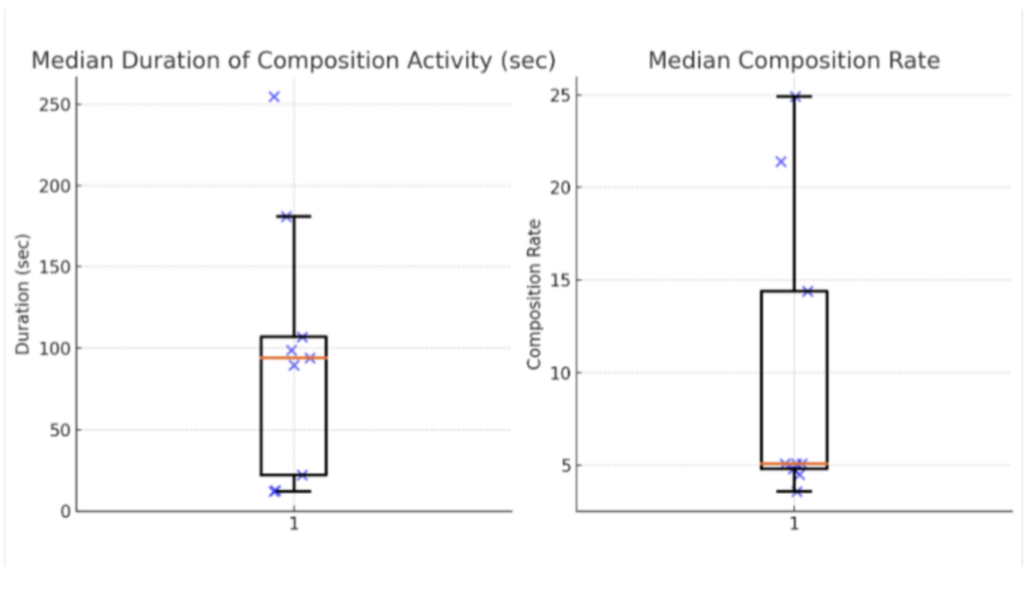
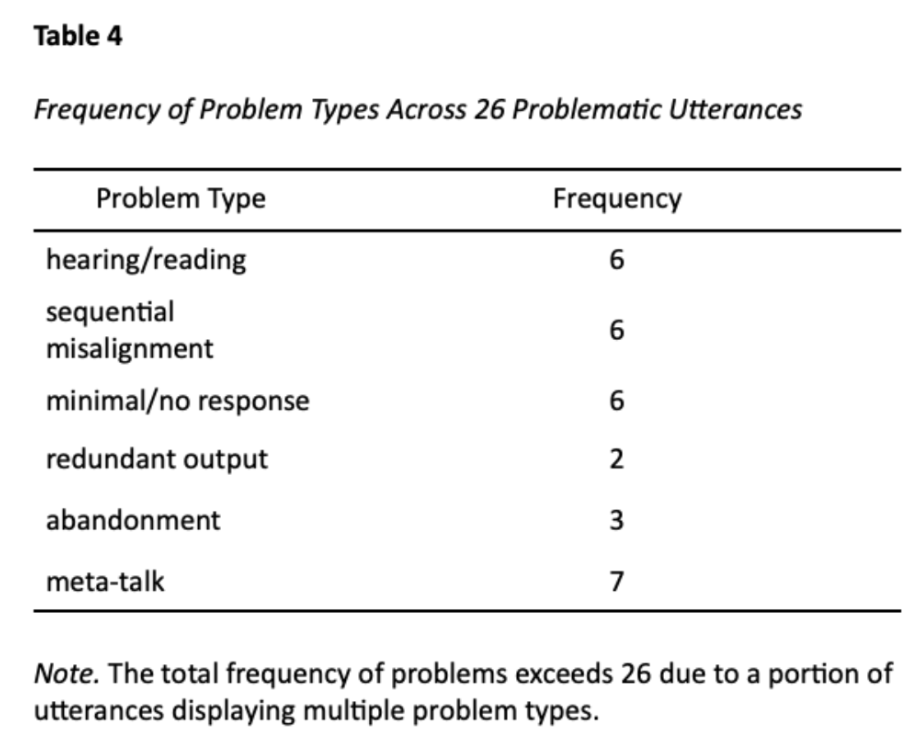
Across the 91 grounded units, 78% contained talk that was concurrent with device users’ AAC composition. Of those grounded units with concurrent talk, 32% were problematic. In contrast, only 15% of grounded units without concurrent talk were identified as problematic. The problems identified included difficulties of hearing or reading, sequential misalignment, minimal or absent responses, redundant output, abandonment, and meta-talk.
These findings suggest that partner talk during AAC composition is not inherently problematic, but it increases the likelihood of temporal-sequential trouble. When partners talk while augmented speakers are composing, the interaction may move forward before the AAC utterance is produced, changing the sequential environment into which the utterance eventually arrives.
We presented this work at the Atypical Interaction Conference and the American Speech-Language-Hearing Association convention. Here is a link to the interactive poster. We are also finalizing a manuscript for submission to Augmentative and Alternative Communication. The paper is intended to introduce the enchronic interaction perspective to the AAC research community and to provide an empirical study of composition delay.
Repair in Interaction
Repair is a central issue in AAC-mediated interaction because composition delay, technology constraints, and the social organization of conversation all affect how communication problems are recognized and resolved. We undertook a series of investigations to examine the prevalence, temporal-sequential dynamics, social antecedents, and consequences of repair in augmented interaction. Major findings from our work on other-initiated and self-initiated repair were presented at ASHA in November 2023.
Repair is especially important from an enchronic perspective because repair practices often depend on immediate access to language to support the precise timing and placement of utterances. AAC users may be more vulnerable to misunderstanding because of composition delay while also having fewer timely resources for correcting those misunderstandings once they occur.
Other-Initiated Repair
We published our first study on other-initiated repair in AAC in 2023. Using both simulated and human performance data, we found that initiating repair within the enchronic temporal order was largely unavailable to most augmented speakers, except through single selections produced at 11 words per minute or faster, or short phrases and utterances produced at more than 55 words per minute. A major AAC device manufacturer has already applied these findings.
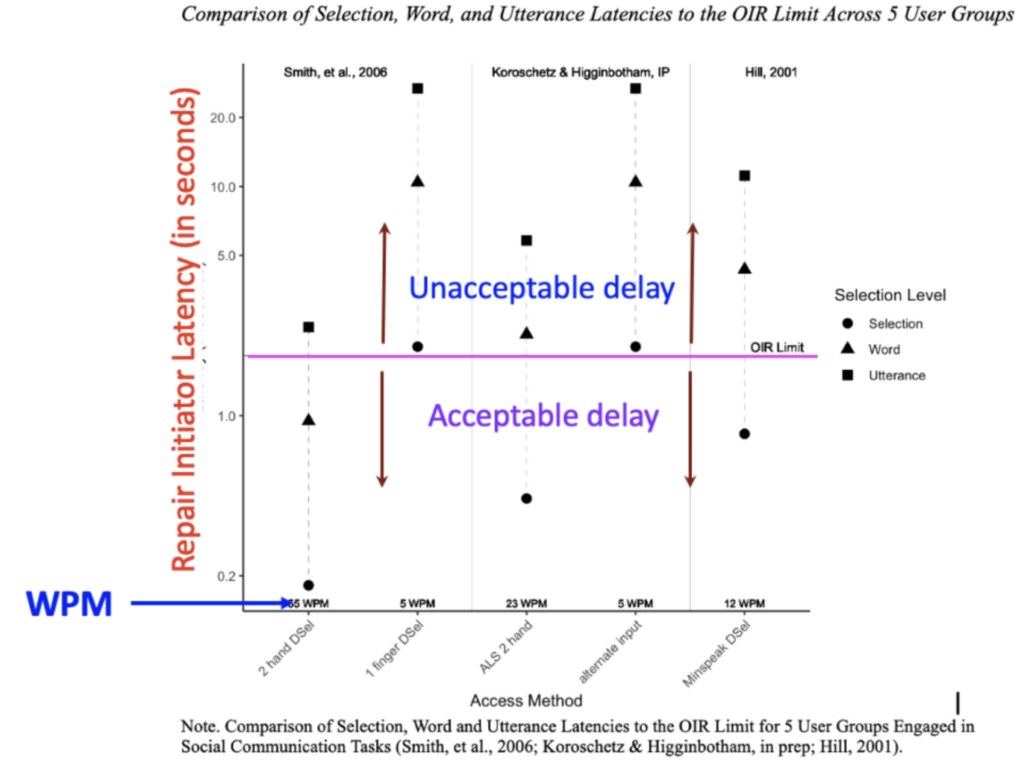
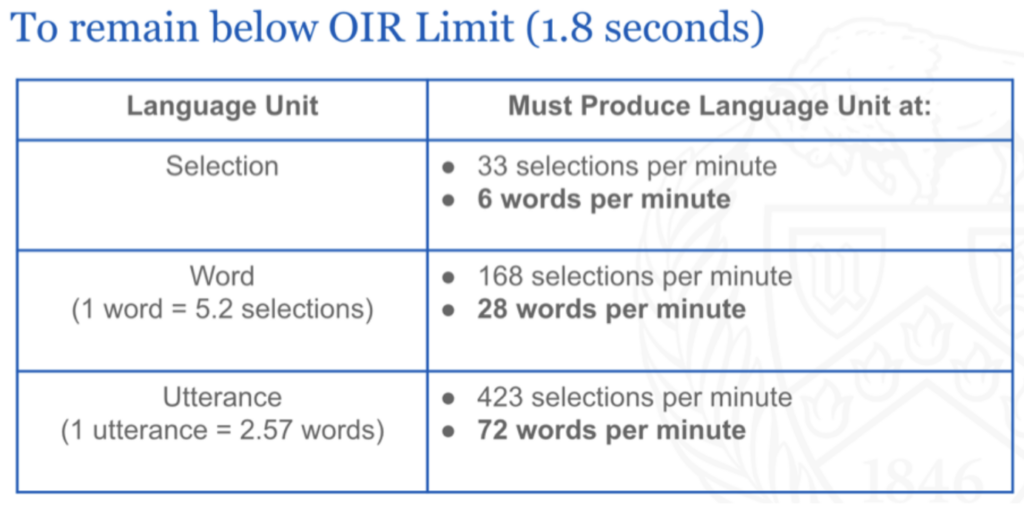
This research demonstrated a fundamental asymmetry in AAC-mediated conversation. While oral speakers can generally initiate repair quickly enough to remain within the unfolding temporal order of conversation, many augmented speakers cannot do so through ordinary device composition methods.
The mechanisms of other-initiated repair in AAC-mediated conversation were further explored in the dissertation research of Antara Satchidanand. Using a mixed-methods design, she adapted a coding scheme designed by Dingemanse et al. (2016) for the cross-linguistic analysis of other-initiated repair and applied it to an expanded version of our composition-delay dataset. .
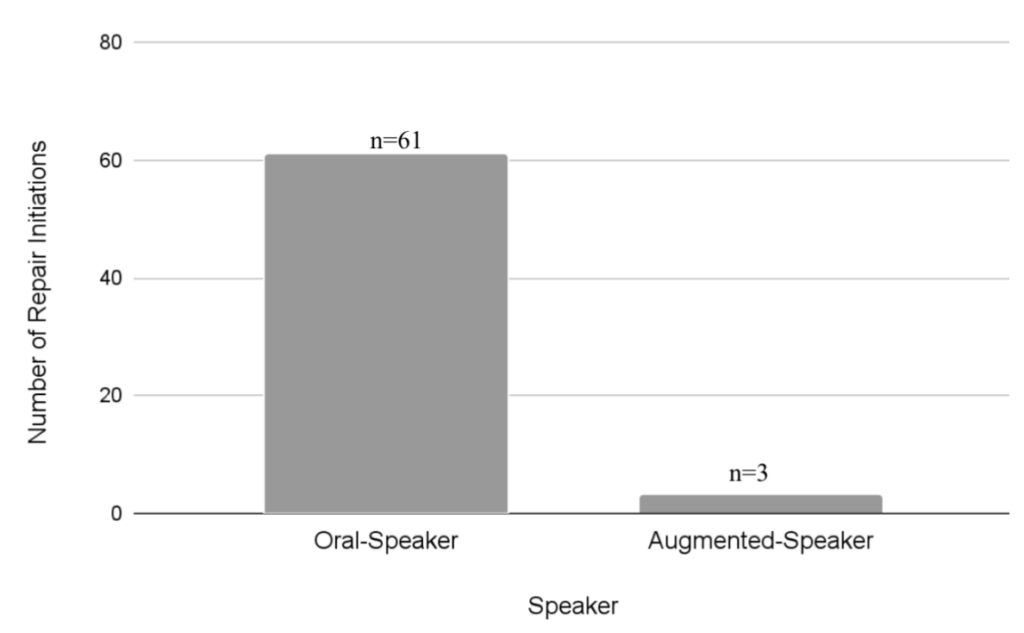
In a preliminary analysis of ten speakers with ALS, Satchidanand found that repair in SGD-mediated conversation differs from repair in typical spoken interaction in several important ways. Repair initiation in augmented conversation was shown to be heavily asymmetric, with augmented speakers contributing only a negligible proportion of repair initiations.
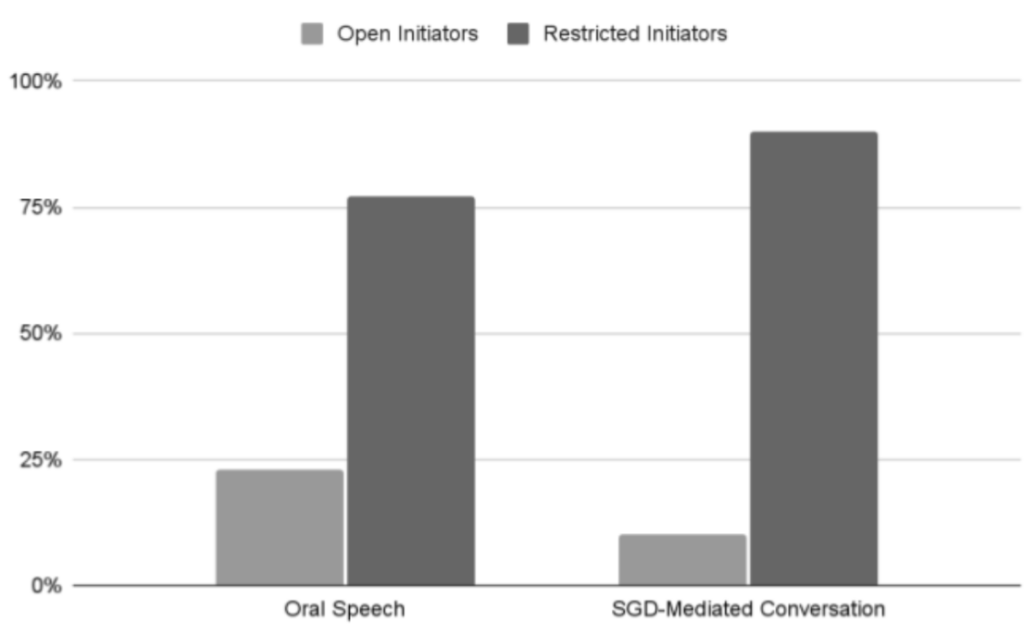
Open-class repair initiations, which request repair without identifying the problematic portion of the trouble-source utterance or specifying the nature of the problem, occurred less frequently than in typical conversation.
Interestingly, a key finding concerned the behavior of the oral-speakers in our sample, who initiated repair differently when in conversation with augmented speakers. Candidate understandings, a type of repair that shifts the effort/costs of repair from the trouble source speaker to the repair initiator, were used by the oral-speakers in our sample more frequently than has been observed in conversations between two oral-speakers.
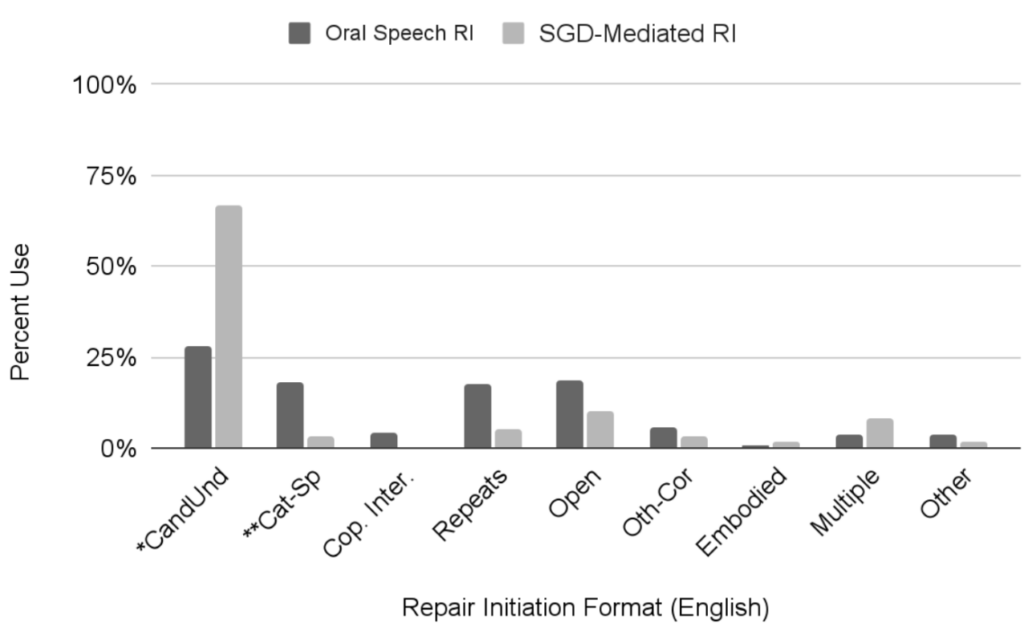
Finally, non-minimal repair sequences, which require more than one attempt to resolve, occurred much more frequently in augmented conversation. Many extended repair sequences involved multiple repair initiations on the same trouble-source utterance, first to clarify accurate perception of the utterance and then to address issues of comprehensibility.
Self-Initiated Repair
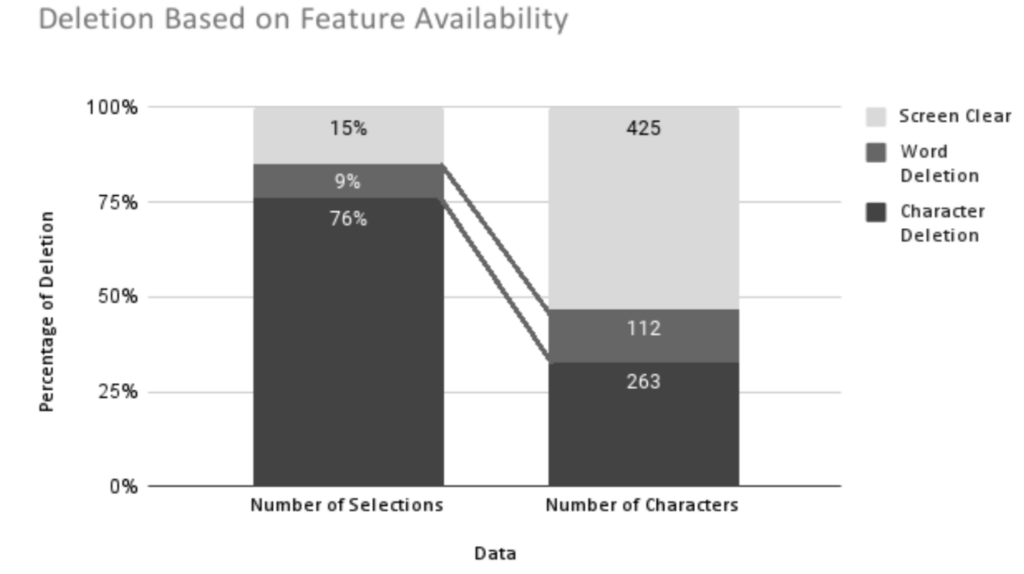
Project Enchrony also examined self-initiated repair in AAC-mediated interaction. First, a simulation study demonstrated the keystroke savings possible when a word-delete option was available in executing self-repair. APP1 below provided researchers with such an option while APP2 included only character deletion and screen clear options.
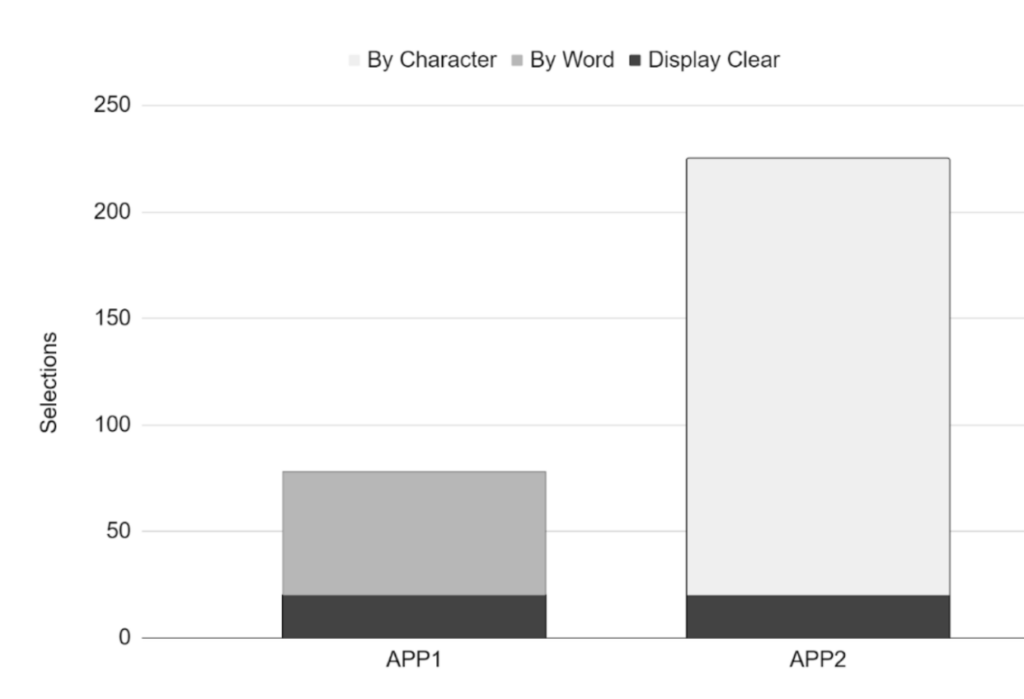
Note: This figure is copyrighted by the authors (Satchidanand, Rayman, and Higginbotham, 2022) and is used with permission.
This study also revealed the keystrokes added to utterance production when self-repair is included with and without the word-deletion option.

The availability of a word- and screen-clear options button substantially improved the efficiency of message selection during self-repair.
Building from this work, in a graduate student research project, Cassandra Vecchio examined self-repair in situ by analyzing task-related interactions from 10 dyads, represented in 30 videos, in which one participant had late-stage ALS. Her preliminary findings, presented at ASHA, showed that self-initiated repair occurred in approximately one-third of augmented speakers’ utterances and accounted for 26% of their keystrokes.
Vecchio’s analysis of deletion types supported these findings: each clear-screen selection deleted an average of 3.5 characters, word deletion removed 1.5 characters per selection, and deleting a single character required an average of 2.3 character-deletion actions.
These findings indicate that current AAC devices are not well configured to support the efficient self-repair and editing practices required during AAC-mediated conversation.
Gabrielle Martino conducted a subsequent analysis of the efficiency of deletion types used by participants in Vecchio’s study, which revealed that while three options for the deletion of message content were available to users, they often did not choose the most efficient option, choosing character-by-character deletion instead.
A manuscript that brings together the results of the simulation and in situ study of self-repair is currently being prepared for submission by the end of June.
Project Enchrony developed from a conceptual concern with conversational timing into a systematic research program on the temporal organization of AAC-mediated interaction. Across the Project Converse funding period, the project produced a multimodal transcription infrastructure, a large video database, grounded unit analysis, empirical studies of composition delay, investigations of other-initiated and self-initiated repair, conference presentations, manuscripts, and design principles for future AAC technologies.
The central finding from Enchrony is that many AAC interaction problems are problems of temporal-sequential organization, not simply problems of vocabulary, communication rate, or message output. Face-to-face conversation unfolds within a narrow enchronic window, where actions are expected to be responsive, sequentially fitted, and close enough in time to remain intelligible as responses. AAC technologies often make it difficult for augmented speakers to act within that window. As a result, utterances that were appropriate when composition began may be heard as late, disconnected, or difficult to place by the time they are finally produced.
Composition delay is therefore not simply slow message production. It reorganizes the interactional ecology. While an augmented speaker is composing, they may be working intensely on their next contribution, but much of that work is invisible to the partner. These periods of invisible progressivity place substantial demands on the partner’s vigilance, who must wait, remain engaged with little evidence of substantive progress, maintain memory of the prior conversational context, and be ready to respond when the postponed utterance is eventually spoken. During this time, we found that many partners continue talking, shift topics, pursue other lines of action, or treat the delay itself as meaningful.
Enchrony’s repair findings further show that many AAC users face a double burden. Composition delay increases vulnerability to misunderstanding by obscuring the timing, target, and relevance of an utterance; at the same time, many users lack reliable access to timely repair initiation and efficient self-repair once trouble occurs. Other-initiated and self-initiated repair studies showed that AAC-mediated repair differs substantially from ordinary spoken repair and often requires more time, effort, and partner coordination.
Together, these findings have direct implications for AAC research, design, and clinical practice. AAC systems should not be evaluated only by whether they produce accurate messages, provide sufficient vocabulary, or increase communication rate. They must also be evaluated by whether they support temporal participation: the ability to respond, repair, interrupt, affiliate, resist, clarify, and coordinate with others as interaction unfolds moment by moment.
The design challenge identified by Enchrony is therefore clear. Future AAC technologies must help augmented speakers use their devices to interact in-time with their partners. This means supporting not only message generation, but also the timing, visibility, repairability, and temporal-sequential placement of contributions within the ongoing organization of face-to-face conversation.
Formerly: Expressive Speech Synthesis
Co-Directors: Higginbotham, Szekely & Possemato
Associate Researcher: Horowitz
Start Date: July 2022
Project Intone was developed to investigate how expressive synthetic speech can better support AAC-mediated conversation. The project emerged from the recognition that conversational participation depends not only on what is said, but also on how it is said: timing, intonation, loudness, emphasis, affect, and stance all shape the social meaning of an utterance.
Our Move research demonstrated that reducing delays in conversational turn-taking allows spoken intonation to become more functionally integrated into social interaction. As conversational timing becomes more natural, intonation can support important interactional functions such as emphasis, referencing, responsiveness, and conversational coordination.

Research Progress
Studies
Summary
Project Intone emerged from the Year 1 Pragmatically Effective Phrases and literature search efforts. As Project Converse examined the interactional demands of AAC-mediated conversation, conversationally appropriate synthetic speech became a major research and development priority.
The rationale for Intone grew out of a problem specific to speech-generating devices. Because SGD-produced utterances are often delayed by message composition, the pragmatic role of intonation is greatly diminished. By the time an utterance is spoken, its sequential placement may already be late, making intonation seem less consequential than rate, vocabulary access, or message formulation. As a result, expressive prosody has often been treated as peripheral to SGD technology development rather than as a central resource for conversational action.
Project Intone was designed to re-examine that assumption. In ordinary conversation, intonation, loudness, rhythm, emphasis, and voice quality help speakers show whether they are asking, resisting, affiliating, teasing, repairing, insisting, softening, or closing a sequence. These features are especially important for short utterances such as “ok,” “no,” “yeah,” or “really,” whose social meaning depends heavily on how they are delivered.
This issue was particularly important for Project Move, which was designed around short, pragmatically powerful words and phrases intended to reduce delay and support near-real-time participation. If these utterances could be produced quickly enough, then intonation might once again become interactionally consequential for AAC users. Intone therefore investigated whether expressive synthetic speech could restore some of the pragmatic force that is often lost when SGD utterances are delayed, flattened, or delivered without controllable prosody.
Collaboration with Eva Szekely
Project Intone was developed in collaboration with Eva Szekely at KTH Royal Institute of Technology in Stockholm, Sweden. Szekely’s work focuses on human-sounding synthetic speech and its relationship to gesture, making the collaboration directly relevant to Project Converse’s interest in embodied, multimodal, and conversationally situated AAC.
The initial plan was to explore Szekely’s emotive speech-synthesis process as a way to record and generate conversationally appropriate synthetic voices. The team aimed to identify the prosodic features needed to accomplish AAC-relevant conversational objectives and to develop speech-synthesis applications that could eventually be used in SGD technologies.
Early development also explored the integration of expressive speech selection with the Open Source Designer and Programmer Interface (OSDPI). One early prototype combined head tracking and facial recognition with intonation selection, using SmyleMouse software to recognize facial and head movements. This work provided an initial proof of concept for selecting among different intonation alternatives through accessible interface methods.
The Kaylie Voice Model
During Year 3, the project concentrated on recording and synthesizing a female voice, Kaylie, for use across Project Move and related Project Converse work. Kaylie, a Buffalo actress, was employed to provide voice samples for single words and short phrases. Because she had acting experience, the team could request specific kinds of performances, such as quiet reading or particular affective deliveries, to help build out the expressive range of the synthesized voice model.
In addition to newly recorded samples, Kaylie donated a number of hours of prior voice recordings to the project. These materials were used to support development of the Kaylie voice model in Szekely’s lab.
In February 2024, the team received Kaylie 3.0 from Szekely’s lab. The goal was to test its feasibility for use in our Move and DEAN-related projects, especially its ability to produce pragmatically useful intonational variants. An example of Kaylie’s natural speech and the synthesized model is shown in the video clip below:
The exploratory platform used to experiment with the speech model is shown below:

Testing Expressive Control
The Kaylie voice model could produce a very realistic voice that could be manipulated for its emotive qualities, however we were unable to reliably control it over a broad or precisely specified range of prosodic variants.
As a result, the team decided to pause use of the Kaylie voice for interface development. This decision did not reflect a failure of the voice model itself, as it remained valuable for experimental stimuli and research on listener perception. What it could not provide, however, was the level of prosodic control needed for the project’s SGD-oriented design goals.
Listener Perception Study
Although the Kaylie voice was not adopted for interface development, it became the basis for a small listener-perception study examining how acoustic differences in synthetic voice quality shaped listeners’ interpretations of speaker intention by voice gender. Presented in Kyoto, Japan, at the 2024 Fall Special Interest Group on Discourse and Dialogue conference, the study extended Intone beyond speech-synthesis implementation to examine how synthetic voice characteristics influence the social interpretation of AAC output. Here is a link to the poster from this conference.
Findings and Implications
Project Intone showed that expressive synthetic speech is essential for conversational AAC, but it is currently difficult to implement in a controlled and usable way. Naturalness alone is not enough. AAC users need speech output that can be shaped for specific social actions, affective stances, and sequential environments.
The Kaylie voice work demonstrated the promise of custom expressive voices, especially for experimental stimuli and research on listener perception. However, it also showed that a voice model may be high quality without being sufficiently controllable for SGD use. For AAC design, the key requirement is not just voice quality, but reliable access to specific prosodic forms.
The shift to Azure TTS shows the value of using a more controllable and interface-compatible speech system, even if it is less personalized than a custom voice model. For Project Converse, controllability became the immediate priority because Move and DEAN required speech output that could be coordinated with pragmatic categories, speech acts, and AI-generated content.
The broader implication is that AAC speech synthesis should be evaluated not only by intelligibility, naturalness, or preference, but also by its ability to support interactional action. Expressive TTS should allow users to ask, resist, tease, repair, affiliate, insist, soften, joke, or disengage in ways that are recognizable to conversational partners.
Lexical and Syllable Emphasis Study
A related Intone study that grew from our Move work examined the possible utility of word emphasis in synthesized speech for speech-generating devices. Although word and part-word emphasis play important pragmatic roles in spoken conversation, including communication repair and clarification of speaker intent, their relevance for SGD design has been underexplored.
This study used the Project Move research study as its data source. Because participants were limited to a fixed set of pragmatically organized SGD vocabulary items, Move provided an ideal context for examining how typically speaking users deployed token emphasis while operating within AAC-like interface constraints. We examined how a trained typical speaker used lexical and syllable emphasis while selecting tokens from the Move interface and produced them with her natural voice rather than synthesized speech. This allowed us to observe how word and part-word stress functioned during interaction while preserving the vocabulary and selection constraints of an SGD system.
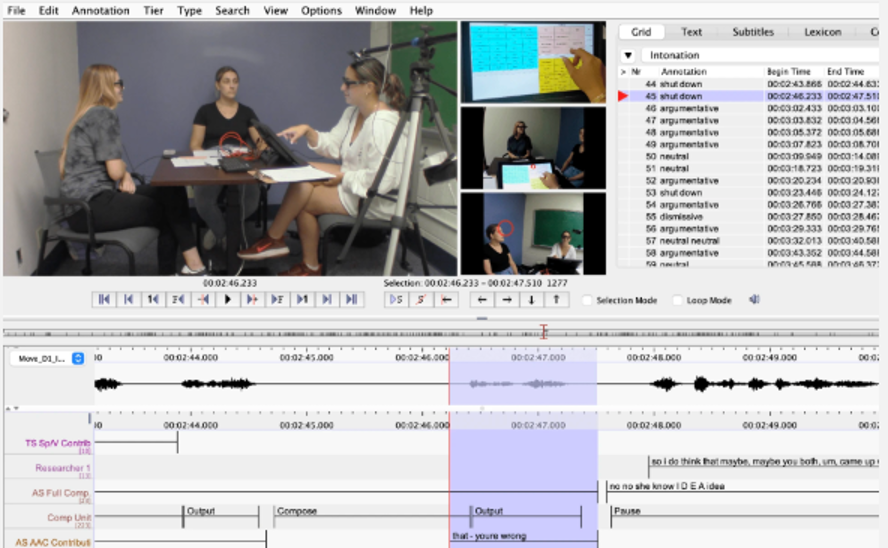
Data collection included eye tracking of both participants, annotation of selected tokens, instances of emphasis, and the pragmatic function of each emphasized token. Emphasis and intonation categories were developed through iterative review of the Move data. A coding scheme was then created, and interrater agreement reached 84% when the second author independently re-categorized the data.
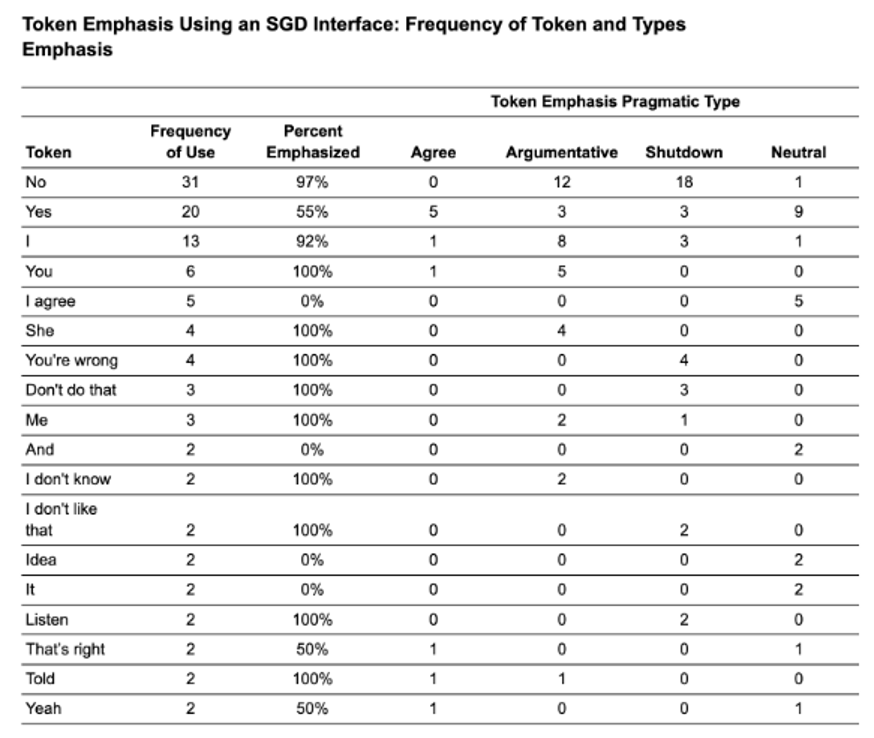
Three pragmatic uses of emphasis were identified: agreement, argumentative emphasis, and shutdown. The SGD user produced 107 tokens during the sampled conversations, 78% of which carried some form of emphasis. Argumentative emphasis was the most frequent category, accounting for 45% of emphasized uses, followed by shutdown at 43% and agreement at 12%.
The most frequently emphasized tokens were yes and no, which accounted for 48% of all tokens used and 49% of all emphasized tokens. Personal pronouns, including I, you, she, and me, accounted for an additional 24% of tokens and 30% of emphasized tokens. Taken together, yes/no forms and personal pronouns accounted for approximately 80% of the emphasized words in the sample.
These findings suggest that even limited access to word- or syllable-level emphasis could improve SGD users’ ability to convey pragmatic meaning during utterance production. The study also strengthens the connection between Intone and Move: Move identified the value of rapid, pragmatically organized utterances, while Intone showed that the interactional force of those utterances may depend on the ability to emphasize particular words or syllables. This finding also informs DEAN by suggesting that AI-AAC systems should not only generate contextually relevant utterances, but also support controllable emphasis and prosodic delivery for key tokens within those utterances.An interactive poster based on this project was presented at the American Speech-Language-Hearing Association convention in 2025. Multiple videos demonstrating this work can be found within the ASHA 2025 Eposter at this link.
Across the Project Converse funding period, Project Intone developed from an expressive speech-synthesis exploration into a focused research and development effort on controllable prosody for AAC. It resulted in a collaboration with Eva Szekely’s lab, early OSDPI-based intonation-selection experiments, the Kaylie custom voice model, server-based testing, a listener perception study, and a strategic shift to Microsoft Azure TTS, followed by ElevenLabs for integration with Move and DEAN.
The central contribution of Project Intone is the recognition that AAC speech output must be designed for conversational action. Synthetic voices must do more than speak selected words clearly; they must help augmented speakers deliver utterances with appropriate timing, affect, stance, and social force.
This work directly informed Project Converse’s broader AI-AAC development. By identifying both the promise and limitations of custom expressive voices, and by shifting toward more controllable TTS systems, Intone helped establish the speech-output foundation for Move and DEAN. Future AAC systems should therefore treat prosody and expressive delivery as core design requirements, not optional enhancements.
Co-Directors: Higginbotham, Mathy & Bizovi
Associate Researchers: Satchidanand, Golleru, Buckley, Hutchinson
Start Date: June 2022
This line of research has contributed to the development of methods for creating more authentic conversational environments in experimental settings, as well as advanced tracking and interaction analysis techniques that enable faster and more detailed insights from our interaction studies.
Current AAC designs often create barriers to sustained social engagement by concealing the augmented speaker’s message composition process from communication partners. While providing partners with visual indicators of conversational progress—such as the ability to view ongoing message composition—can increase engagement and support conversational flow, it can also introduce new challenges. In particular, partner comments or reactions to partially composed messages may interrupt, delay, or unintentionally redirect the augmented speaker’s intended contribution.

Research Progress
Studies
Summary
Project Engage originated from a central question in augmentative and alternative communication (AAC): how can contemporary high-tech AAC systems preserve the engagement, immediacy, and shared participation that were often inherent in interactions using traditional low-tech communication boards, while also supporting the autonomy, independence, and efficiency made possible by speech-generating devices? The project was first conceptualized as the “Twentieth Century Communication Board” then reframed as the “21st Century Communication Board”, and ultimately emerged as Project Engage. Across these iterations, the project has remained focused on understanding how AAC interface design shapes face-to-face interaction, particularly the degree to which communication partners remain visually, cognitively, and socially engaged while an augmented communicator constructs a message.
The rationale for the project emerged from earlier interaction research by Higginbotham and colleagues on low-tech communication boards. In those interactions, the communication partner typically remained in continuous contact with the augmented communicator’s message construction process as the message was built element by element. Both participants oriented visually either to the board, to each other, or to another shared referent. This arrangement supported co-attention, co-construction, and rapid collaborative participation. However, the same features that created engagement also imposed costs. Communication partners could become fatigued by the level of vigilance required, and augmented communicators were often dependent on partners to interpret, hold, or help complete messages. Thus, low-tech boards offered an important model of engaged interaction, but one that did not fully support communicator autonomy or reduce partner burden.

The transition to speech-generating devices represented a major advance in AAC. SGDs allow augmented communicators to construct and speak their own messages using synthesized speech and a wide range of access methods. These systems increase independence and reduce direct reliance on the partner. However, prior work by Higginbotham and colleagues also showed that typical SGD use can reduce conversational engagement. Because message construction is usually slow, often in the range of 5–15 words per minute, the augmented communicator must devote sustained visual attention to the device while the communication partner waits without access to the emerging message. In this configuration, message construction becomes largely invisible to the partner. The partner may disengage, miss cues that a message is being composed, talk over the augmented communicator, misinterpret pauses, or lose the thread of the interaction. Project Engage was designed to address the interactional problem of how SGD configuration might better support the ongoing relationship between participants as messages are being built.
For the purposes of Project Engage, conversational engagement is defined as the observable actions demonstrating coordinated co-attention of participants to each other or to another person, object, or event. Engagement is understood as an external manifestation of the participants’ ongoing intersubjective relationship, in which both parties work to understand each other’s perspective as the interaction unfolds over time. This definition is particularly relevant for AAC-mediated interaction because message construction places asymmetric attentional demands on the augmented communicator and the communication partner. The augmented communicator must attend to the device to formulate the message, while the partner may not have a clear visual or interactional role during that process. Project Engage therefore focused on AAC configurations that make message construction more visible and interactionally available to the partner without simply recreating the dependency demands of traditional communication boards.
2022: Re-imagining the Word and Letter Board
In 2022, the project began as an effort to re-imagine the traditional word and letter board on an e-paper hardware platform. The original goal was to explore the intimacy and in-time co-constructive properties of low-tech devices and determine whether those properties could be preserved or enhanced unobtrusively in a modern interface. During this initial phase, the team investigated large-format e-paper platforms but determined that available e-paper technologies were not yet adequate for the project’s needs. As a result, development shifted toward using the Open Source Design and Programmer’s Interface, or OSDPI, on an iPad and related platforms as an initial research environment. This shift allowed the team to focus less on hardware limitations and more directly on the interactional design questions at the center of the project.
2023: The 21st-Century Communication Board
By 2023, the project had evolved into the “21st Century Communication Board.” At this stage, Pamela Mathy joined the project in a leadership role, bringing expertise in AAC and conversation analysis. The team also expanded to include collaborators with expertise in computer science, industrial and systems engineering, communication repair, and AAC research. Development work focused on creating an OSDPI-based interface that could simulate and extend the properties of a low-tech communication board while enabling systematic research. A critical technical advance during this period was the development of logging capabilities for the OSDPI platform in collaboration with Project Open. These logfile capabilities made it possible to directly track user-device interaction and integrate device-selection data into ELAN video annotation files. This integration was important because it allowed the team to study device performance and social interaction together, rather than treating device use and conversation as separate phenomena.
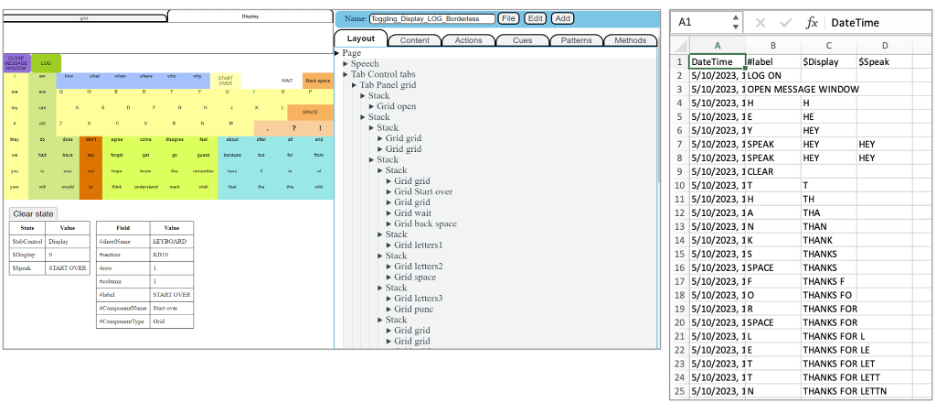
During this phase, the team also began trialing the OSDPI interface across multiple platforms, including iPads, Windows laptops, and AAC devices such as the GridPad 15. In parallel, the team developed training materials and research protocols. These early development activities were essential because the research required participants to use AAC-like interfaces with enough proficiency that observed differences across conditions could be attributed to interactional configuration rather than simple unfamiliarity with the device.
2023-2024: Developing Testing and Training Infrastructure
In 2023-2024, with a move from interface development into systematic pilot testing, the “21st Century Communication Board” became Project Engage. The team developed and conducted a pilot study examining engagement-related behaviors, including mutual gaze, interaction style, and communication problems, across different AAC configurations. While designing this study, the team identified the need for structured device training to establish participant “interface literacy.” In response, the team developed a Vocabulary Trainer that prompted participants to locate pre-programmed words or spell words not available on the interface. The trainer recorded timing and accuracy data and prepared the data for analysis in R. This training system became an important methodological contribution because it provided a way to quantify and support participants’ learning of the interface before experimental data collection.
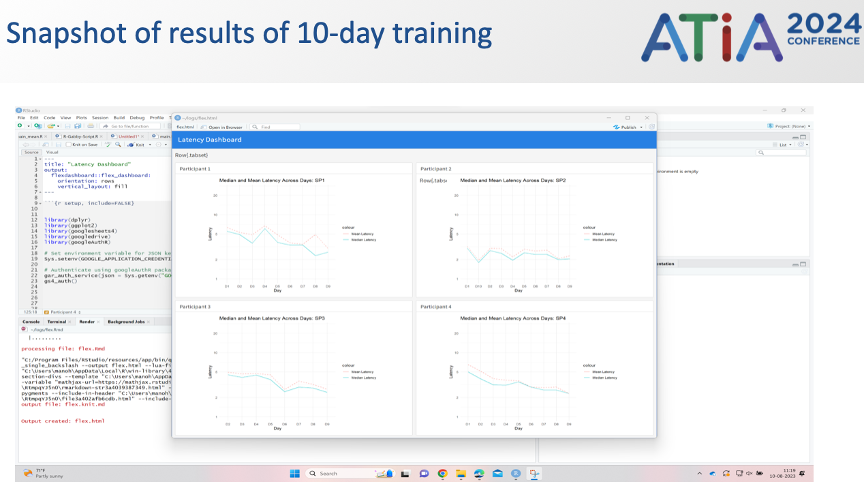
The 2023-2024 pilot study involved two trained dyads who completed conversations across multiple tasks using three communication modes: a traditional communication-board mode visible to the partner, a communication-board/SGD hybrid mode with a text display, and a traditional SGD mode in which the partner sat across from the augmented speaker without visual access to the AAC display. Each dyad completed six 10–20 minute conversations across interface configurations and task types, including wayfinding and problem-solving activities. To analyze the data efficiently, the team developed a continuous time-sampling approach for video coding.
Pilot findings showed substantive differences in mutual gaze across device configurations. Mutual gaze was used more often in the communication-board and SGD-See mode than in the traditional SGD mode. These results suggested that interactions were more orderly and more engaged when the communication partner could see the communication display and monitor message construction. The findings also suggested that a hybrid SGD-See configuration may offer an important compromise between the high engagement of communication-board interaction and the independence afforded by traditional SGDs.

2024: Larger Study of Five Communication Conditions
In 2024, building on the pilot findings, the team implemented a larger study with five dyads and five communication conditions. This study was designed to evaluate the effects of AAC output mode and partner access to message construction on conversational engagement behaviors across two communication tasks. The five conditions were: Speaking Mode, in which both participants used natural speech; SGD-Traditional, in which the augmented speaker used an SGD with the message window visible only to the augmented speaker; SGD-See All, in which the typical speaker could see the augmented speaker’s full screen, including the message window and construction interface; SGD-Listener-Facing, in which the SGD presented text to the partner through a real-time listener-facing display along with spoken output; and Communication Board, a simulated low-tech no-output board requiring sustained visual engagement between partners. The two tasks included a Map Task, emphasizing asymmetric information transfer, and a Scenario Task, emphasizing collaborative problem-solving.


The larger study used a within-subjects design with five adult dyads composed of long-term partners. Within each dyad, one participant was randomly assigned to the augmented-speaker role and the other to the typical-speaker role. Able-bodied adults served as augmented speakers in order to isolate the effects of AAC modality and device configuration from individual motor, sensory, or cognitive differences. The study included training, warm-up trials, and data collection trials, with each dyad completing ten trials across the five communication modes and two task types. Multimodal data streams included video of the social interaction, video of the device display, eye-tracking video from both participants, OSDPI device logs, post-trial questionnaires, and individual debrief interviews.
The data preparation and analysis process required synchronizing and rendering multiple video streams for ELAN annotation. The OSDPI logfile data were also integrated into ELAN, allowing researchers to examine device selections alongside social interaction. Coding was conducted in 10-second intervals across talk, gaze, and collateral tiers. The talk tier captured orderly turn-taking, disrupted turn-taking, co-construction, and augmented-speaker composition. The gaze tier captured mutual gaze and other patterns of coordinated visual attention. The collateral tier included repair sequences and message abandonment.
Findings and Implications
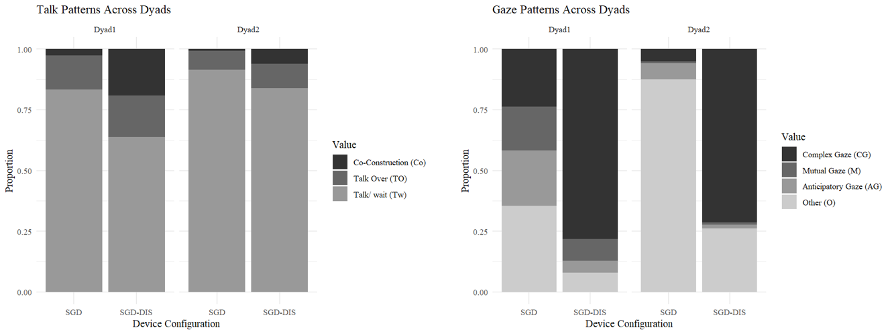
Findings from the larger study supported the project’s central hypothesis: AAC configurations that made message construction visible to the partner supported stronger engagement. Speaking Mode served as the benchmark for typical conversational rhythm, showing typical turn-taking in nearly all intervals. Across AAC conditions, typical turn-taking was reduced, but the distribution of co-construction, disrupted turns, and augmented-speaker composition varied by configuration. The Communication Board condition showed the highest level of co-construction, likely because mutual visibility and the absence of synthesized speech required sustained partner attention. SGD-See All also supported engagement, although the presence of synthesized speech and a message window appeared to allow the partner to disengage at times while awaiting completed output. SGD-Listener-Facing supported some partner awareness through word-by-word display but provided fewer opportunities for real-time co-construction. SGD-Traditional showed the lowest co-construction and the highest disrupted turn-taking, likely because the partner had no access to the augmented speaker’s message until the message was spoken.
Gaze findings showed a similar pattern. In the Communication Board, SGD-See All, and SGD-Listener-Facing conditions, where the typical speaker could monitor message construction in real time, mutual gaze occurred in more than half of the coded intervals. In contrast, SGD-Traditional showed the lowest mutual gaze and a distinctive pattern in which the typical speaker looked toward the augmented speaker during message construction in only about one-quarter of intervals. These findings suggest that visual access to message construction gives the communication partner an interactional role during composition, supporting alignment, shared attention, and engagement.
Participant debrief interviews reinforced the quantitative findings. Participants strongly preferred the SGD-See All condition, describing it as seamless and intuitive. SGD-Listener-Facing was ranked second, although participants noted that it felt slower because the partner-facing display presented each word only after it was completed. The Communication Board condition ranked third, with participants noting high cognitive and memory demands. SGD-Traditional was least preferred because it offered little real-time feedback and made it difficult for the partner to stay engaged. Together, the behavioral and subjective data indicate that AAC system design should be evaluated not only in terms of message output, but also in terms of how well it supports interaction, shared attention, and the co-construction of meaning.
For an interactive summary of the larger study, see the 2025 American Speech-Language Hearing Association Poster.
Related Thesis Research on Partner-Facing Displays
A related thesis project by Manohar Golleru examined the impact of adding a front-facing partner display to a traditional SGD configuration. Using a single-case comparative design with two dyads, the study compared traditional SGD interaction with interaction using an SGD plus a front-facing partner display during wayfinding tasks. Participants completed training, experimental trials, questionnaires, and post-study interviews, and the interaction data were coded using a continuous time-sampling protocol similar to the larger Project Engage study. Results showed that the partner display increased co-construction and shared/complex gaze and reduced passive waiting, indicating that the display helped typical speakers remain engaged in the augmented speaker’s message construction. However, the display also increased some talk-over and repair behaviors, suggesting a tradeoff: partner access can support engagement but may also encourage premature guessing or over-participation. These findings have been presented at a national conference and will be submitted for publication.
Across the Project Converse funding period, Project Engage progressed from a conceptual effort to reimagine the low-tech word and letter board into a systematic research program examining how AAC interface design affects engagement in face-to-face conversation. The work produced a functioning OSDPI-based research platform, device-logging capabilities, a Vocabulary Trainer, a catalog of comparable interaction tasks, pilot data, a larger five-dyad experimental study, thesis research on partner-facing displays, national dissemination, and manuscripts in preparation or under review. The project’s central contribution is the demonstration that conversational engagement in AAC is strongly shaped by whether the communication partner can engage and coordinate with the augmented speaker’s message construction process. This finding has direct implications for AAC design and clinical practice: future systems should be designed not only to produce speech, but also to make the process of message construction interactionally available in ways that preserve augmented-speaker agency, support partner engagement, and sustain the moment-by-moment intersubjective relationship that makes conversation possible.
Director: Higginbotham
Co-Directors: Fulcher-Rood & Bizovi
Research Staff: Mathy, Golleru, Satchidanand, Possemato, Buckley, Hutchinson, Horowitz
Prototype Tester / Research Associate: Hutchinson
Start Date: January 2022
Rather than treating AAC primarily as a tool for composing full propositional messages, Project Move proposes a focus on short words, phrases, discourse markers, questions, continuers, repair initiators, disagreements, and other interactional moves that can be fired off quickly, allowing speakers to manage and control the flow of conversation. This is a novel shift from a standard word-frequency-based vocabulary organization to one of increased pragmatic efficiency.
The central design premise is that AAC users need to be able to deploy utterances that shape the course of conversation (i.e., manage turn-taking, initiate repair, etc.) within the temporal and sequential demands of face-to-face interaction. This is necessary because:
- Conversation is organized around actions, not only words.
- Short pragmatic utterances can exert substantial conversational control, including claiming the floor, resisting, repairing, affiliating, disagreeing, redirecting, and collaborating.
- Rapid access to preconstructed words and phrases can reduce composition delay and support more in-time participation.

Research Progress
Studies
Summary
Project Move began as the Pragmatically Effective Phrase Project, or PEP, in January 2022. The project was initially conceived as an AAC interface, along the lines of Contact’s Quickfires, that would use pragmatically effective words and phrases to help augmented speakers leverage control and agency during interaction.
The rationale for Move emerged directly from Project Converse’s broader concern with composition delay and the temporal organization of AAC-mediated conversation. Many AAC systems are optimized for vocabulary access, word prediction, or full message construction. These are important functions, but they do not always support the kinds of brief, timely conversational contributions that accomplish communicative actions, such as claiming a turn at talk (e.g., “Wait”), initiating repair (e.g., “What?”), or aligning with another conversant’s prior contribution (e.g., “I agree”), which allows speakers to manage real-time interaction. In ordinary conversation, utterances like “wait,” “no,” “go ahead,” “what do you mean,” “I agree,” “that’s not what I meant,” or “can I say something” can substantially alter the course of interaction. Move was designed to investigate whether giving AAC users rapid access to these types of utterances could improve their ability to participate in time.
The project also served as an early R&D platform for several components that later became important across Project Converse, including OSDPI development, device data logging, expressive speech synthesis, participant-focused iterative development protocols, interaction-based device design, and hardware/software prototyping.
Early Development: PEP and the Paper Interface
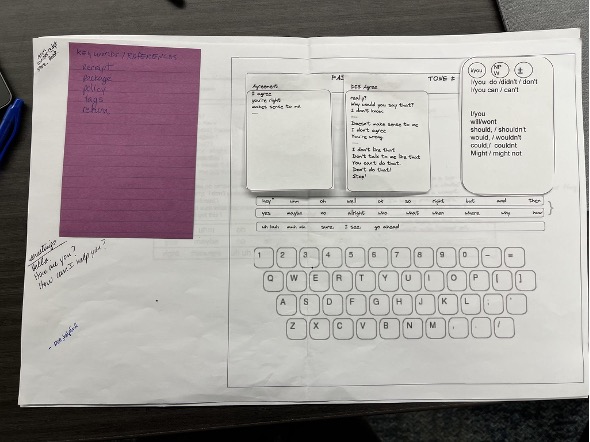
During Year 1, the project focused on developing the basic concept and initial content for a pragmatically organized AAC interface. This work included identifying candidate words and phrases, examining relevant interaction literature, and considering how to organize discourse markers, strategic questions, repair forms, and short social responses for rapid use during face-to-face interaction.

During Year 2, the project was renamed Project Move to align with our focus on communicative actions, also known as “moves” in interaction research, and the team continued developing the interface through a series of paper prototypes. By spring 2023, the paper interface had reached approximately version 10. These early paper versions were used to explore content organization, conversation topics, participant training needs, and the interactional demands of using pragmatic utterances in real time.
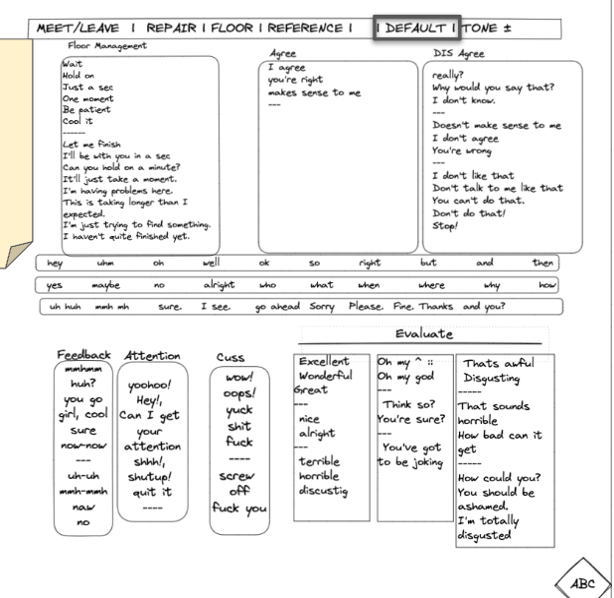
The paper interface also helped identify a major methodological challenge: participants could not simply be handed a Move display and expected to use it effectively in conversation. To evaluate the interface properly, users needed training in both operational proficiency and pragmatic use. They needed to know where utterances were located, how quickly they could retrieve them, and how particular Move tokens could be used to accomplish actions such as interrupting, disagreeing, initiating repair, asking for help, claiming the floor, or changing topics.

Interface Analysis and Design
During Year 3, the team used video data from research team members interacting with the Move paper interface to inform the transition from paper to a digital OSDPI interface. Conversations were coded for interface selections, and state-transition diagrams were created to identify commonly selected tokens, frequently accessed categories, and sequential patterns of use.
the top level of the Move interface.
These analyses informed the organization of the digital Move interface. Categories such as core moves, repair, topic change, floor management, and other pragmatic functions were arranged to support fast access and reduce the need for deep navigation.
Transition to OSDPI
During Year 4, Project Move transitioned from a paper-based prototype to a dynamic OSDPI interface. This transition allowed the team to begin bench testing, organize vocabulary through OSDPI’s spreadsheet-based content format, and eliminate the need to navigate across multiple levels to access core Move vocabulary.
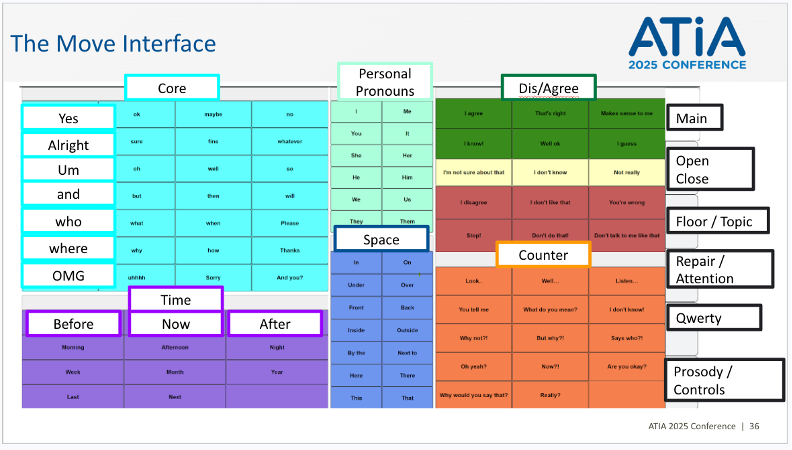
The digital interface used tabs to reveal additional panels of phrases while maintaining core Moves across levels. The top-level organization was based on the state-transition analyses shown above, which helped identify high-frequency categories and items that needed to remain immediately accessible. This structure was intended to preserve rapid access while still allowing the interface to contain a broad set of pragmatic utterances.
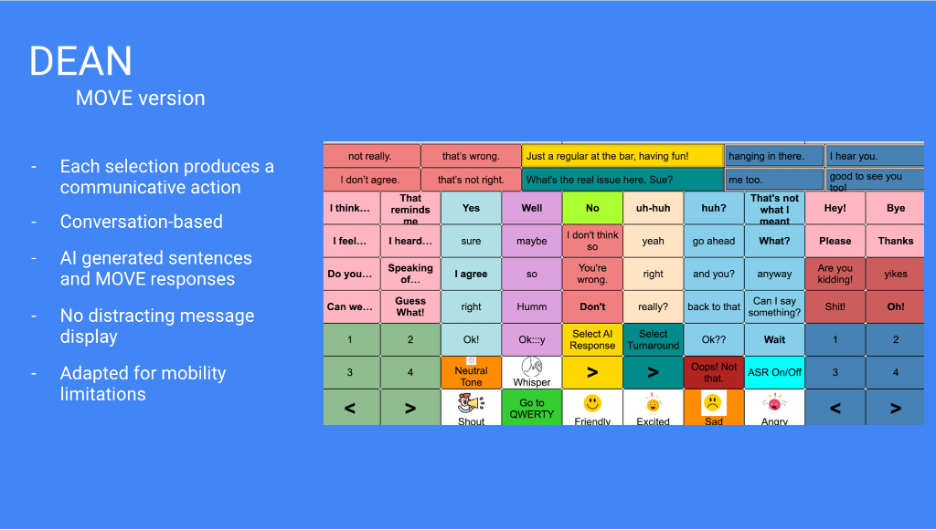
Integration with DEAN
By Year 5, the resulting Move interface had been integrated into DEAN, Project Converse’s AI-AAC probe. This integration reflected a key design insight: AI-generated utterances and rapid pragmatic Moves address different but complementary interactional needs.
DEAN supports contextually responsive AI-generated utterance options, while Move provides quick access to high-frequency pragmatic actions that allow an augmented speaker to participate immediately. Together, these systems combine two forms of AAC support: generated content for contextually specific responses and preconstructed pragmatic Moves for rapid conversational control.
This integration positions Move as a core component of the broader Project Converse design trajectory. Move contributes the interactional “short game” of AAC: the quick, timely Moves that sustain progressivity, support agency, and allow the augmented speaker to remain visibly active in the conversation while longer or more specific utterances are being generated or composed.
Building the Training Infrastructure
A major Year 3 contribution was the development of training infrastructure for both device use and social interaction. Katrina Fulcher-Rood led the development of protocols and materials for device and interaction training. This work was motivated by the realization that an accurate evaluation of Move required participants who could use the interface with sufficient speed, familiarity, and pragmatic understanding.
The training protocol had three major components. First, participants were trained to locate Move tokens quickly and accurately. Second, they were asked to use Move tokens to respond to pragmatic questions and scenarios. Third, they received modeling and instruction on leveraging Move utterances during conversational interactions.
Fulcher-Rood also drew on her background in theater and stand-up comedy, working with a stage actress to develop social-interaction warm-up modules that promoted familiarity, timing, collaboration, and willingness to take on conversational roles. These materials were designed to help participants become comfortable using Move not only as a vocabulary display but as a resource for performing interactional actions.
In collaboration with Pam Mathy, Fulcher-Rood also developed task materials for repeated testing across different communication situations, including persuasion, direction giving, arguing, and informal chat. This work contributed to a broader Project Converse need for comparable interaction tasks that could be used across iterative interface-development studies.
Pilot Study and Single-Case Replication
During Year 4, the team conducted, coded, and analyzed a replicated single-case pilot study using the dynamic Move interface. A graduate student research assistant was trained to use the interface through a structured protocol developed for Projects Engage and Move. The participant completed approximately 20 hours of training to become proficient in the content and interactional requirements of the system. This included both operational proficiency and interactional practice. Operational training focused on knowing where utterances were located and how quickly they could be retrieved. Interaction training focused on using the interface to engage in conversation, including interrupting, disagreeing, asking for help, initiating repair, and collaborating with a partner. Each dyad also received additional training to increase familiarity and ease of interaction, following a protocol developed with input from an acting coach.
Pilot Testing featured the trained Move user interacting with two typical speakers using a single-case research design. Each dyad participated in 12 interaction sessions, including eight conversation trials and four probe sessions. The probe sessions compared Move with a traditional SGD condition. Although full coding was still underway, the team conducted a preliminary turn-transition analysis of the probe sessions.
Turn-Transition Time
The preliminary turn-transition analysis showed that, with training, most of the augmented-speakers’ turns using Move occurred within one second of the preceding utterance, closely approximating the natural turn-taking rhythm of the oral speaker. In contrast, the median latency in the bimanual traditional SGD condition was approximately four times longer.
It should also be noted that for many of the SGD turn transitions that were under 2.5 seconds, composition was initiated before the oral speaker had completed their prior speaking turn. These shorter SGD latencies therefore reflected preemptive composition, rather than the augmented speaker’s ability to respond rapidly after the partner’s turn was complete.
This is a significant finding because it suggests that the trained Move user was able to remain synchronized with conversational partners within what the lab refers to as Now-Time: the interval in which participants can maintain in-time interaction.
Preliminary video analysis also showed that the Move user, who was using their natural voice to produce tokens in lieu of synthesized speech, regularly varied intonation patterns for short core utterances such as “yes”, “no” and across personal pronouns to create word emphasis conveying distinct pragmatic meanings. This finding reinforced the importance of pairing rapid utterance access with expressive delivery. It also opened the door to another study that examined this use of word emphasis which is described in Project Intone.
Project MOVE demonstrated that rapid access to pragmatically organized words and phrases can support more symmetrical, in-time AAC-mediated interaction. After systematic training, the participant in the augmented-speaker role used the MOVE-based AAC system to participate in turn-taking with little or no temporal gap, producing interruptions, disagreements, insults, repairs, and collaborative contributions in real time. These findings show that reducing turn-transition delay does not depend only on faster typing. It also requires AAC interface designs that prioritize timely conversational action, pragmatic function, and interactional control.
MOVE reframes AAC vocabulary design around what speakers need to do in conversation. Its utterances allowed the augmented speaker to interrupt, agree, disagree, initiate repair, hold the floor, redirect a topic, ask for help, affiliate, resist, and collaborate before the relevant interactional moment had passed. In this sense, MOVE was not simply a phrase page; it was an interactional system for supporting conversational agency.
The project also showed that training is essential. MOVE was not self-explanatory as a conversational interface. Participants needed to learn the layout, locate utterances efficiently, understand the pragmatic categories, and develop fluency in using a limited set of tokens to accomplish specific conversational actions. This training requirement is challenging, but it is also important: it shows that interactional competence with AAC technologies is learned, practiced, and situated.
MOVE also clarified the connection between pragmatic vocabulary and expressive speech. Many MOVE utterances are short and multifunctional, so their meaning depends heavily on timing, stance, and delivery. The participant’s ability to vary intonation during the MOVE pilot study showed that pragmatic AAC design cannot be separated from expressive speech design. Short utterances such as “no,” “yeah,” “ok,” or “wait” become interactionally powerful only when they are delivered quickly enough and with a vocal form that fits the moment.
Across the Project Converse funding period, MOVE developed from the Pragmatically Effective Phrase Project into a functioning OSDPI-based research interface for studying rapid pragmatic AAC. The project produced paper and digital prototypes, a refined MOVE vocabulary, state-transition analyses, training protocols, task materials, a dynamic OSDPI implementation, a replicated single-case pilot study, preliminary turn-gap findings, and integration into the DEAN AI-AAC probe. Its central contribution is the demonstration that AAC systems should support not only message construction, but also fast, flexible, and expressively deliverable resources for managing the moment-by-moment organization of conversation.
Bridging Communication, Language, and Literacy Through Child-Led Learning.
Conducted by the Center for Literacy and Disability Studies at the University of North Carolina at Chapel Hill, the work emphasizes child-centered, multimodal communication and challenges traditional adult-directed approaches. Using video data and methods informed by conversation analysis, the team highlights how communication is co-constructed using varied forms of expression, including body movements, gesture, gaze, vocalizations, and AAC. Findings reinforce the importance of flexible, responsive, and relationship-centered practices, with resources such as the Framework for Observing Communication Interactions (FOCI) with Early Communicators supporting professionals in advancing inclusive communication, language, and literacy experiences.
Between 2022 and 2025, the team analyzed video recordings to examine how instructional practices and partner behaviors influence communication, how children use embodied and aided forms of AAC, and what barriers may limit participation. Project goals include using moment-by-moment observation to better understand how meaning is co-constructed in interaction, and the importance of following the child’s lead, recognizing unconventional or emerging communication as meaningful, and creating authentic opportunities to connect communication and language learning within real interactions, particularly in literacy contexts.
Building on these findings, the 2025–2027 phase focuses on translating research insights into tools and guidance that support more responsive and inclusive practice. This includes helping professionals make informed decisions about turn-taking, recognizing and responding to embodied communication, fostering equitable participation, supporting diverse forms of expression, including aided AAC, and measuring progress in meaningful, interaction-based ways. Explore an expanding collection of open‑source tools and insights:
