In the previous post, we explored how we’ve implemented an uninformed AI system to enrich the AAC user experience. Now, let’s delve into the other half of the AI framework we’re building – the informed AI and how we’ve given it a personalized touch.
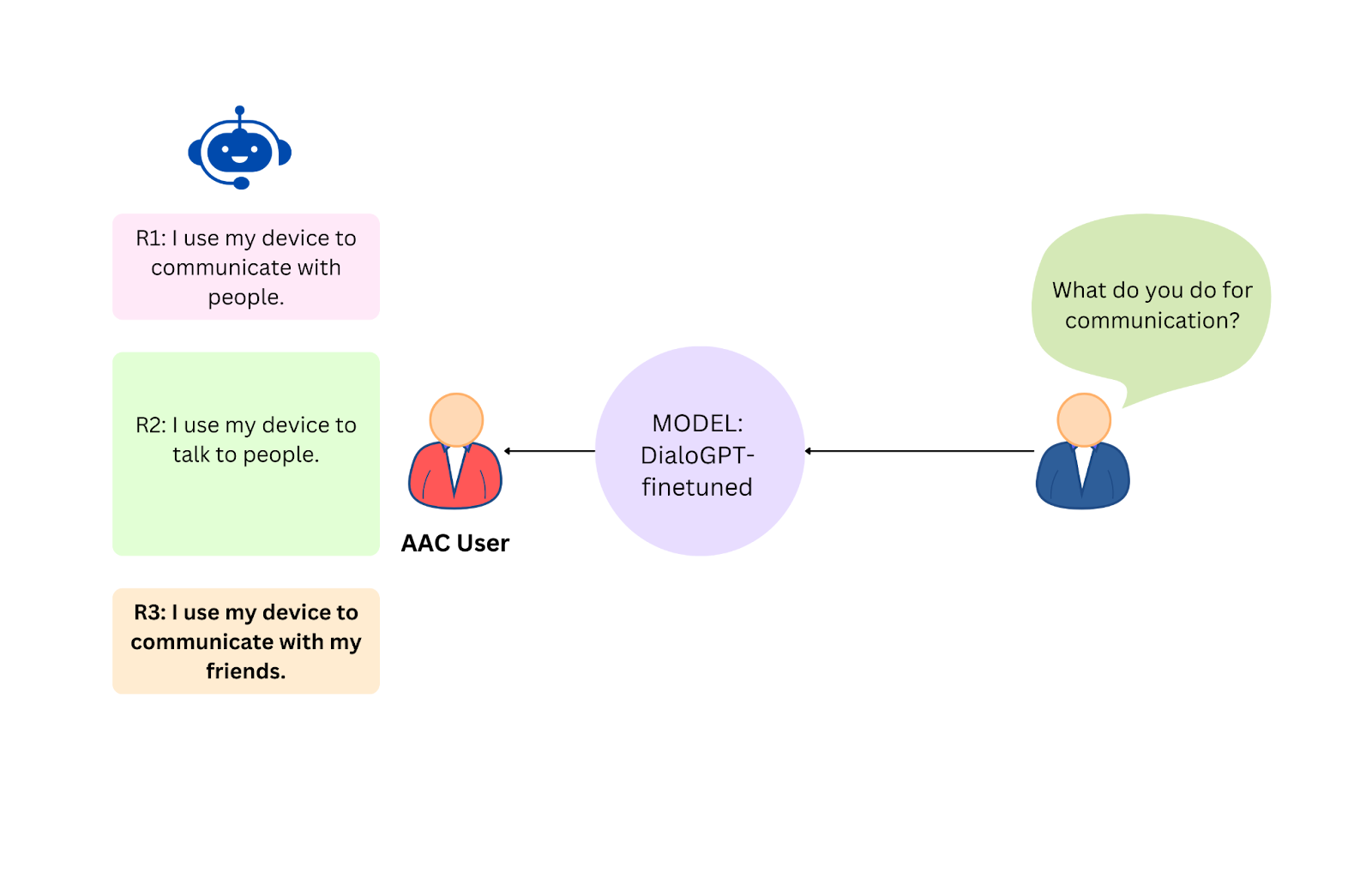
Unlike the uninformed AI, the informed AI is not about random chitchat. Instead, it’s designed to converse on subjects directly relevant to our AAC user. To make this possible, we’ve created a unique dataset derived from a book written by the AAC user. This dataset equips our AI to be “informed” about the user’s interests, experiences, and style of language use.
To create the informed AI, we utilized a small DialoGPT model and fine-tuned it using the personalized dataset. DialoGPT is a conversational model designed to deliver human-like dialogues, making it ideal for generating responses that align with the AAC user’s narrative.
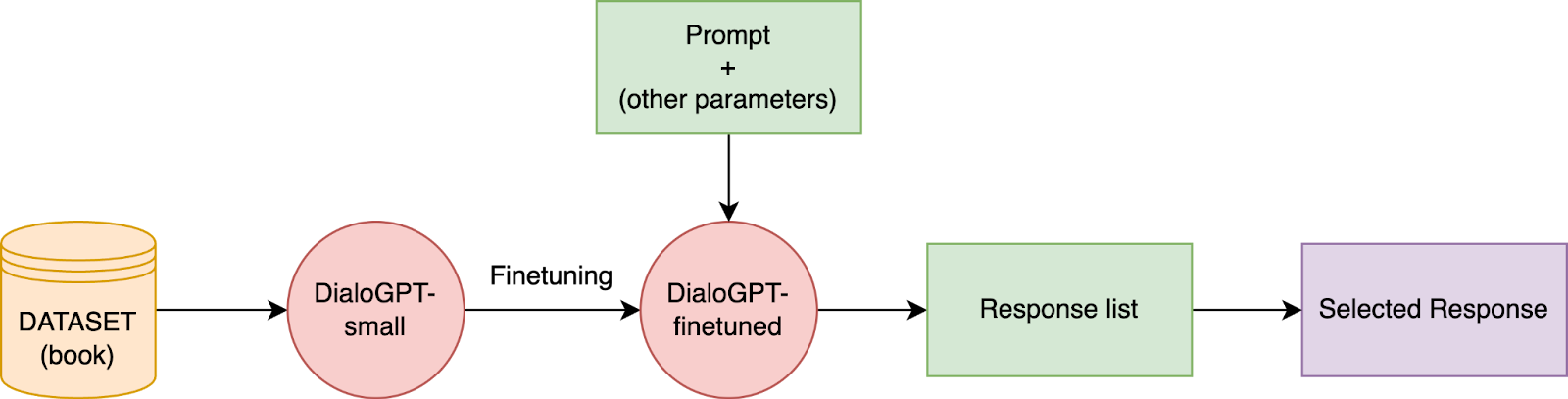
Response Generation Overview
Although DialoGPT performs decently, its output is less potent than the BlenderBot, which we used for the uninformed AI. One reason for this could be the dependency of the model’s performance on its parameters and the influence of the training data. We suspect that using a larger model, like DialoGPT-large, might have boosted the response quality. For BlenderBot and DialoGPT, we’ve added parameters to our API: ‘prompt’, ‘num_response’, ‘context’, and ‘temperature’. These parameters are crucial to achieving varied responses.
By blending personalized AI models with user-specific data, we’re pioneering the future of AAC systems. Our work promises to make communication more accessible, individualized, and enriching for users. Keep following our journey to stay updated on our exciting project!