Dynamic, Expressive, Augmented Narrator (DEAN) is an AI-enhanced AAC research platform designed to help people who use speech-generating devices participate more effectively in face-to-face conversation. Rather than requiring users to compose every message from scratch, DEAN listens to a communication partner’s speech, generates possible responses, and presents them for the user to select, preserving the user’s control, identity, and agency. It integrates research on conversational timing, rapid pragmatic actions, partner engagement, personalization, and expressive speech to support communication that remains connected to the flow of interaction. As a research probe, DEAN is being used to investigate whether conversational AI can help augmented speakers stay in time, in control, and recognizably themselves during real-world conversations. You can try out the interface yourself on the Demo Tab.
System Architecture
Personalization
Interface
Field Testing
Timing in Conversation
Integration Point
Development
Summary
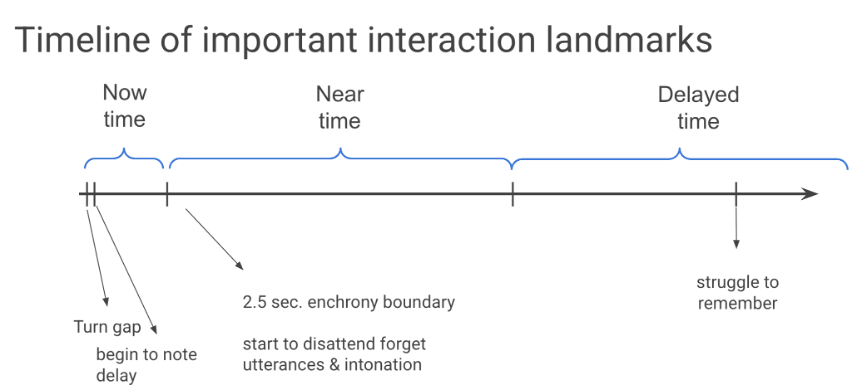
For decades, speech-generating devices have helped people compose and speak messages, but they remain poorly suited to the temporal and sequential organization of ordinary face-to-face interaction. Conversation unfolds enchronically—that is, in time: each action is fitted to what has just happened and helps shape what can happen next. Participants manage this flow through words, gaze, gesture, facial expression, overlap, continuers, repair, agreement, disagreement, and topic shifts, often within only a few seconds.
The composition constraints of SGDs disrupt this organization. While an augmented speaker is composing, the partner may not know what action is underway or which prior turn the emerging utterance is designed to address. During that delay, partners may continue talking to fill the silence, shifting topics, or commenting on the delay itself. As Project Enchrony showed, by the time the SGD utterance is spoken, the interactional environment may have changed enough that its relevance is harder to recognize.
Thus, composition delay is not simply slow message production. It can change the sequential status of an utterance, making an otherwise appropriate contribution harder to place, more likely to be misunderstood, or more vulnerable to being treated as late, irrelevant, or disconnected from the ongoing conversation.
Project DEAN was developed to explore whether conversational AI could help close that gap. Rather than asking an augmented speaker to compose every utterance from scratch, DEAN listens to the communication partner, generates possible responses, and presents those options to the augmented speaker for selection. The goal is not to replace the speaker, but to reduce the burden of composition while preserving the speaker’s control, identity, and agency.
From the beginning, DEAN was designed as a research probe, not a commercial device. Its purpose is to let us study what happens when AI enters AAC-mediated conversation:
- Can the system respond quickly enough to enable augmented speakers to use their devices in NOW and NEAR TIME?
- Are the generated utterances relevant and factually correct?
- Do they represent the augmented speaker’s point of view and current stance in the conversation?
- Do they represent the interactional context, i.e., setting, participants, shared history?
- How does the augmented speaker interact with the AI during face-to-face social interaction?
- What role does the AI take in a conversation? What points of view does it represent?
- How should DEAN be designed to enable the augmented speaker to maintain pragmatically effective, engaged interactions?
- Does speech prosody change when augmented speakers can use their devices within the NOW and NEAR time boundaries of the enchronic temporal-sequential frame?
- Do DEAN’s contributions support or undermine the speaker’s self-presentation?
- Does DEAN help the partner remain engaged?
- How does DEAN represent the interactional context, i.e., setting, participants, shared history?”
- Can AI help augmented speakers remain in time, in control, and recognizably themselves during face-to-face conversation?
These questions shaped the entire development process.
Conversational timing became the central design challenge for DEAN. The system needed to operate within the temporal demands of conversation, not simply generate fluent language. This meant that DEAN also had to be evaluated according to other interactional criteria: sequentially fitted, personally appropriate, and usable by the augmented speaker.
To guide this work, we developed three social-interaction criteria for AI-AAC:
- Sufficiency and Sincerity: Does the response provide what the partner needs to understand, while remaining truthful and acceptable to the augmented speaker?
- Timing and Sequencing: Does the response arrive quickly enough to remain connected to the prior turn?
- Content and Manner: Does the response fit the speaker’s style, stance, self-presentation, and desired level of disclosure?
These criteria helped us move beyond ordinary AI benchmarks. A response can be grammatical and relevant in a general sense, but still fail as an AAC utterance if it is too late, too generic, too revealing, too formal, or simply not something the user would choose to say.
DEAN did not develop in isolation. It emerged from the broader Project Converse effort to understand why current AAC technologies remain poorly suited to face-to-face conversation and which design principles might better support augmented speakers in real interaction. Over the course of our earlier research, we came to see that the central design problem was not simply how to help someone produce a message. The deeper problem was how to help them remain active, visible, responsive, expressive, and socially present within the ongoing flow of conversation. Each of the projects we engaged in addressed a facet of this larger question and contributed to DEAN’s development.
Enchrony provides the temporal-sequential foundation for work on DEAN. It showed that conversation is organized in time and that many augmented speakers are forced to operate their technologies outside the enchronic frame in which ordinary conversational responses are expected, recognized, and understood. Move responds to that problem by developing rapid access to short, pragmatically powerful words and phrases—continuers, repair initiators, agreements, disagreements, interruptions, social responses, and topic-management moves—that allow augmented speakers to act before the interactional moment has passed. Engage addresses the partner-coordination problem by examining how interface configurations affect shared attention, visibility of message construction, and mutual engagement during AAC-mediated interaction.If Enchrony identified the importance of timing, Move identified the value of short, pragmatically focused language, and Engage identified the importance of partner coordination, Intone addresses how AAC utterances should sound when delivered—and whether they are delivered soon enough for vocal form to matter. In ordinary conversation, intonation, word stress, loudness, rhythm, and voice quality help speakers distinguish actions such as accepting, resisting, questioning, repairing, affiliating, or closing a sequence. However, in SGD-mediated interaction, utterances are often delayed long enough that the pragmatic force of intonation and word stress may be weakened or lost. After several seconds, the prior turn may no longer be active in the same way for the partner; the sequential moment has shifted, and the expressive contour of the utterance may no longer carry the same interactional impact. DEAN brings these strands together in an AI-enhanced AAC probe.
DEAN is our attempt to build an interactional AAC system in which timing, language, interface design, partner coordination, and expressive speech are treated as mutually dependent. The shared design principle across Project Converse is that AAC systems should be evaluated by how well they support participation in the temporal, sequential, embodied, and social organization of face-to-face conversation. The goal is not only to help augmented speakers produce messages, but to help them remain in time, in control, and recognizably themselves within the interaction.
Initial discussions about DEAN began in 2022, and active development began in 2023 as large language models became widely available. The first phase focused on whether LLMs could generate plausible AAC response options based on a partner’s spoken turn. This early work was promising, but it also revealed how difficult the problem really was.
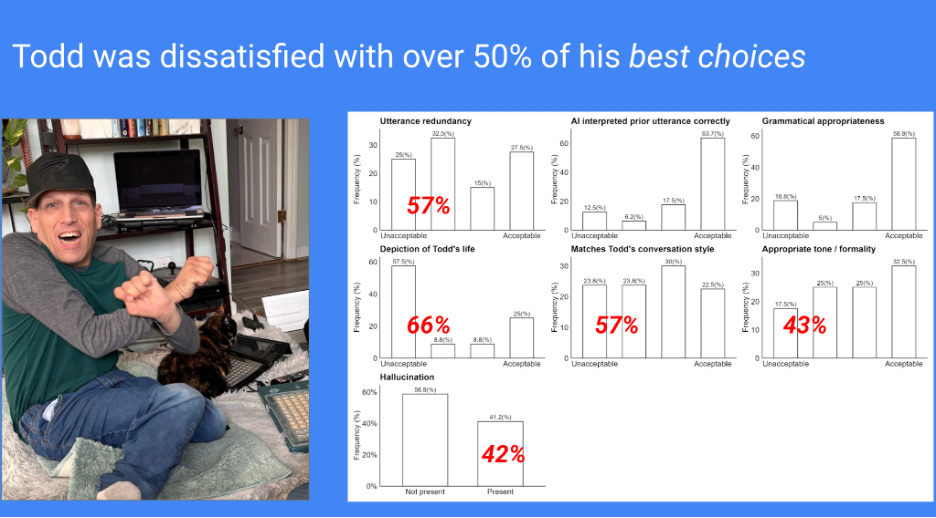
Todd Hutchinson played a central role in this phase. Todd is a lifelong SGD user, co-researcher, and prototype evaluator. His autobiography provided a rich source of personal material for exploring whether DEAN could generate responses grounded in his life history, experiences, and conversational identity. The team used this material to personalize the system, then evaluated how well the generated responses aligned with Todd’s perspective.
The results were mixed. Research by Sayantan Pal and members of CADL showed that the large language model (LLM) trained on Todd’s book outperformed a variety of other LLMs (Pal, et al., 2024). Also, DEAN could generate fluent, sometimes humorous, and often topically relevant utterances. However, many responses still did not work for Todd. Some of the language used by the LLM was not the language Todd was accustomed to using. Some disclosed information in ways he would not choose. Other utterances were redundant, overly polished, or interactionally awkward. This was a major turning point: training on background materials helped, but it was not enough. DEAN needed to support not just topical relevance, but speaker-aligned utterances — responses that Todd could accept as his own in that moment.
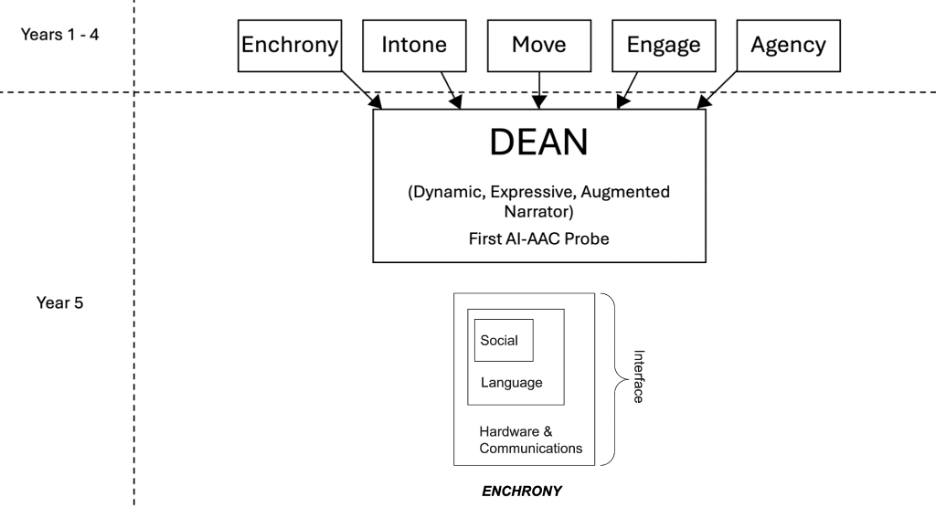
As DEAN developed, it became clear that the system could not be understood as simply “an LLM attached to an AAC device.” DEAN is a layered AI-AAC system with four interdependent layers.
The Hardware and Communications layer manages the technical flow of the system. It includes hardware, server communication, cellular connectivity, automatic speech recognition, text-to-speech, speech output, and logging. This layer determines whether DEAN can reliably capture partner speech, process it, return responses, and speak the selected utterance in the field. This layer is discussed in greater detail in the Hardware and Communication sections.
The Language layer generates and organizes candidate utterances. It includes the LLM, prompting strategies, personalization, light RAG, persona information, action-sequence prompting, and emerging discourse memory. This layer determines whether DEAN can produce language that is relevant, personal, non-redundant, and interactionally useful. This layer is addressed more fully in the LLM and Personalization sections.
The Social layer represents the prompting sent to DEAN that influences its conversational behavior. This includes details about the augmented speaker’s personality and preferences (Persona), as well as fine-tuning DEAN’s responsiveness in providing relevant spoken actions in response to interpreting partner talk. These will be discussed in the Personalization section of this report. This layer is examined in greater detail in the Personalization section.
The Interface layer is the visible and actionable representation of DEAN (buttons, layout, object behavior, etc.) that determines how the augmented speaker – and their partner – sees, evaluates, and uses DEAN in their interactions. All the other layers interact with the interface, making its features – including its AI—usable or unusable for conversation. DEAN’s development has therefore focused on aligning all four layers. A more detailed discussion of this layer appears in the Interface section.
Since January 2026, DEAN has been used for field testing with 2 participants, each using DEAN interfaces customized to their access and representation needs. This study represents much of our research design efforts this year. The design, implementation and initial results of the study are presented in the Field Testing Section of this project.
Across Project Converse, DEAN developed from a diverse set of AAC-related interaction projects, to early experiments with large language models to a field-ready AI-AAC research probe used in our AI/social interaction research. Its central contribution is not merely that it adds AI to AAC, but that it provides a way to study what AI must become in order to support real conversation.
DEAN integrates the major strands of Project Converse. Enchrony provided the temporal framework. Move provided rapid pragmatic action. Engage highlighted partner coordination and interface visibility. Intone contributed expressive speech and prosody. Discourse memory added continuity across turns. Together, these components make DEAN a functional model for studying the future of conversational AAC.
The guiding question remains: Can AI help augmented speakers remain in time, in control, and recognizably themselves during face-to-face conversation? DEAN is our research platform for answering that question.
Directors: Higginbotham, Golleru
Associate Researchers: Buckley, Agarwal
Start Date: April 2023
DEAN’s hardware and network infrastructure evolved over four years from a multi-device laboratory prototype to a web-based system that participants access through a browser link on their own devices. This progression was not linear. Building this infrastructure required solving a series of interconnected engineering problems over the grant period: developing a stable server platform, integrating ASR and speech synthesis with an AAC interface, connecting a language model to live conversational input, and reducing end-to-end latency to a level that could support real interaction. Each phase produced working components while also revealing the constraints that shaped the next design, and these cumulative efforts became the hardware and communication foundation for DEAN, our Dynamic, Expressive, Augmented Narrator.
The earliest architecture, developed in 2023, established the core processing pipeline: partner speech is captured through a microphone, transcribed via ASR, sent to a language model for response generation, and returned as synthesized speech output through the OS-DPI interface. Todd Hutchinson served as the initial prototype evaluator during this phase, and his written materials, including a 60-chapter memoir, were used to study how personal information affected the relevance of AI-generated responses. This phase confirmed that the pipeline was technically viable but left latency, portability, and system stability unresolved. It also defined the technical requirements that would guide subsequent development: the system had to receive partner speech, convert it to text, generate relevant utterance options, display those options through OS-DPI, and produce speech output fast enough to support live conversation. It also needed to log system events and user selections so that we could evaluate timing, response quality, and interactional fit during research sessions.
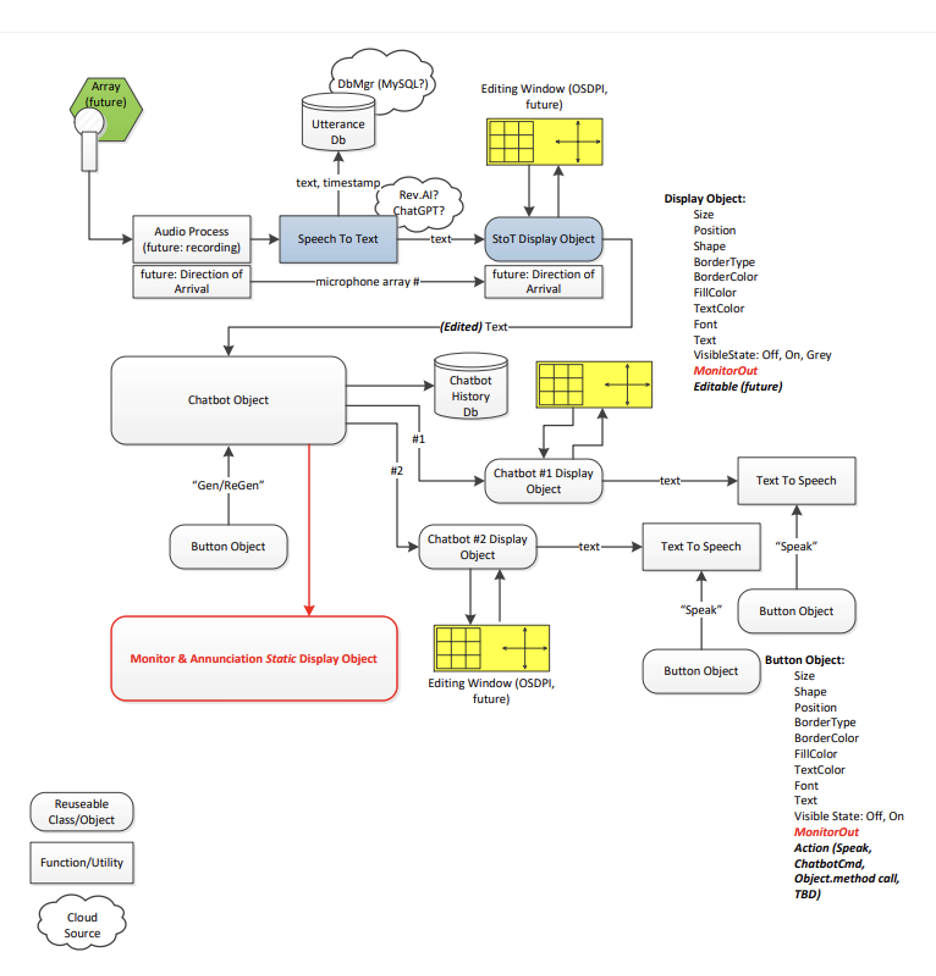
In 2024, we purchased and installed a dedicated server for AI development and connected OS-DPI to external AI services. We also developed a Raspberry Pi-based hardware configuration with an attached microphone, battery power, and cellular connectivity. The Raspberry Pi handled speech capture and managed communication among the partner, augmented speaker, OS-DPI interface, ASR, LLM (BlenderBot, GPT-4), and TTS components. This architecture supported portable testing and let us isolate the contribution of each component to latency and reliability. It also clarified that carrying external hardware into participant sessions was not sustainable as a long-term testing strategy.

A significant source of instability during this period was the tunneling process used to route transcripts from the Raspberry Pi to the server. We tested cellular and mobile connectivity options to reduce reliance on participant Wi-Fi, but these were unstable in practice. We then replaced tunneling with direct HTTP posting, so ASR transcripts were transmitted to the backend server as soon as they were generated. This change reduced a recurring failure point without requiring changes to other system components. We also modified the speech recording workflow. Earlier versions required the augmented speaker to press a record button before each partner’s utterance, which introduced an unnatural interaction burden: the user had to anticipate when the partner would speak, activate recording, wait for transcription and response generation, and then select a response option. We moved recording and speech transfer into OS-DPI directly so the browser could access the device microphone, send speech to the ASR system, receive the transcript, and forward it to the server without requiring manual input between turns. A related challenge arose when partners continued speaking after an initial utterance was recognized, causing subsequent speech to exceed the LLM input buffer’s capacity. We addressed this by giving the augmented speaker a control that lets them choose whether to incorporate the additional partner utterance into a new round of response generation or to proceed with already-generated options. This gives the augmented speaker agency over the conversational pace rather than forcing the system to resolve the timing automatically.
We also migrated the project from Google Cloud Platform to a dedicated on-premises server at the University at Buffalo (UB), maintained by the university’s IT department. We had initially used cloud services because they were fast to set up and flexible for early experiments. Over time, they became expensive and created limitations when we needed additional RAM or GPU support for locally serving large language models. The UB server eliminated monthly hosting costs, gave us direct control over hardware upgrades, including GPU access, and provided institutional support for maintenance, backups, and security. Hosting human-subjects data on UB infrastructure also strengthened our compliance posture. The UB server now hosts OS-DPI along with several web applications, providing a stable and sustainable platform for all ongoing development.
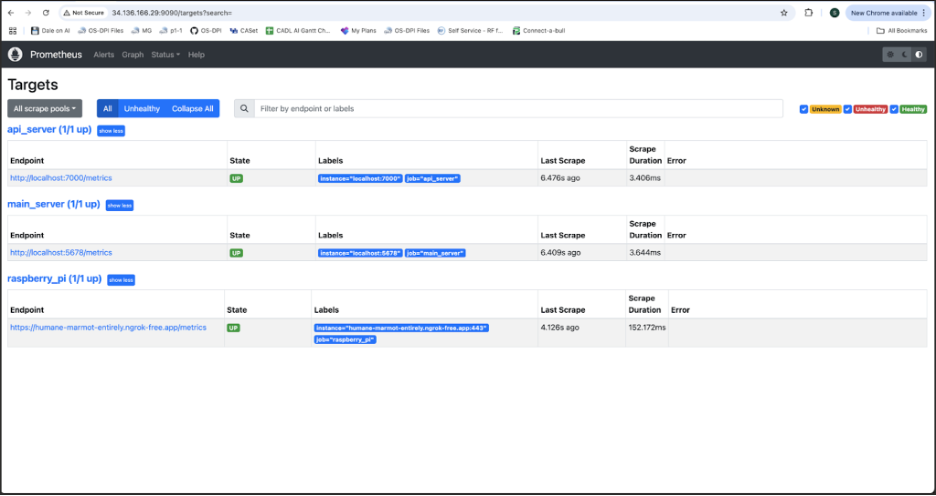
As DEAN became more distributed across OS-DPI, ASR, the LLM, speech synthesis, and server-side routing, we added Prometheus and Grafana to monitor system behavior during live testing. Prometheus collected metrics at the system and service level: API status, Raspberry Pi connection state, server activity, request timing, response-generation latency, connection health, and processing behavior across sessions. Grafana rendered these metrics in a dashboard we monitored in real time during testing.
This infrastructure was necessary because most of DEAN’s early failures did not involve a single component breaking outright. Instead, they arose from small delays, brief interruptions, and misattributed errors distributed across components. Prometheus captured these signals continuously. Grafana let us identify where delays accumulated, whether the server and web interface were communicating correctly, whether the Raspberry Pi remained connected, and whether the system was stable enough for participant testing. The result was a shift from post-session guesswork to real-time diagnosis, which became especially important as DEAN transitioned from a Raspberry Pi-based prototype to a web-based system accessed by participants on their own devices.
This same focus on system visibility also shaped our work to integrate participants’ everyday AAC systems into DEAN. For Hutchinson, we connected his Minspeak device to DEAN through Bluetooth so that his own device output could enter the system’s communication pathway. This integration added a new networking and attribution challenge: DEAN needed to distinguish between partner speech captured through ASR and augmented-speaker output coming from the AAC device. This distinction was important for two reasons. First, DEAN needs to recognize the augmented speaker’s self-composed utterances as part of the ongoing conversation, not only as selections from AI-generated options. Second, the augmented speaker’s contributions must be preserved in discourse memory so the system can maintain conversational coherence across turns. We continued to refine speaker attribution so that DEAN correctly identifies Hutchinson as the source of his Minspeak output rather than misattributing it to his partner.
In Year 5, we transitioned DEAN from the Raspberry Pi-dependent prototype to a fully web-based system. Participants received a URL pointing to their personalized OS-DPI interface and could open DEAN on their own device using their own internet connection, microphone, and speakers. The server no longer needed to be paired with participant-side hardware for testing to proceed. This change reduced setup time, eliminated equipment transport, and made DEAN deployable for remote and field-based sessions.
Concurrent with the shift to web-based delivery, we replaced the language model backend with Llama 70B served through Groq, moving away from the GPT-4 and Azure TTS configuration used in earlier testing. End-to-end LLM response time decreased from approximately 10 seconds in 2023 to approximately 1 second in Year 5 testing. This reduction mattered practically: a 10-second delay between partner speech and the appearance of response options is too long to support live turn-taking, while a 1-second delay is within a range that participants can use in face-to-face conversation. We also integrated ElevenLabs for speech synthesis, which produced more natural-sounding output through the participant’s own device audio compared to earlier Azure TTS solutions. The web-based DEAN setup now combines personalized OS-DPI interfaces, Deepgram ASR, Llama 70B through Groq, retrieval-augmented generation (RAG) memory, persona information, action-sequence prompting, MOVE utterances, and ElevenLabs speech synthesis into a system that participants can access from their own devices.
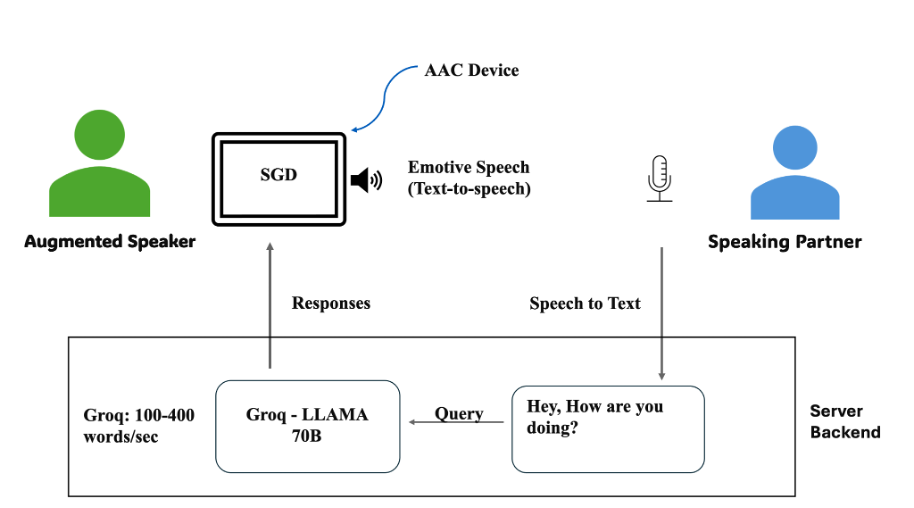
Each infrastructure decision across the grant period, from server migration to ASR integration to latency reduction, shaped what DEAN could do in practice. By Year 5, the system no longer required lab-managed equipment or external hardware. Participants could access their personalized DEAN interface from their own devices, in their own settings, which is the practical condition for the broader participant testing that continues in Year 5 and beyond.
Action Sequences
Discourse Memory
Next Steps

A “persona” represents a specific type of user or customer within a target audience, often used in marketing and design to understand their needs, behaviors, and motivations (Wikipedia, 2024).
A central goal of DEAN is to ensure that AI-generated communication reflects the individual using the AAC system rather than producing generic responses. To accomplish this, we developed a persona framework that captures characteristics such as personality, demographics, lived experiences, physical abilities, interaction style, and important relationships. These elements are used to guide the AI toward responses that better align with the user’s context-based identity, preferences, and conversational patterns.
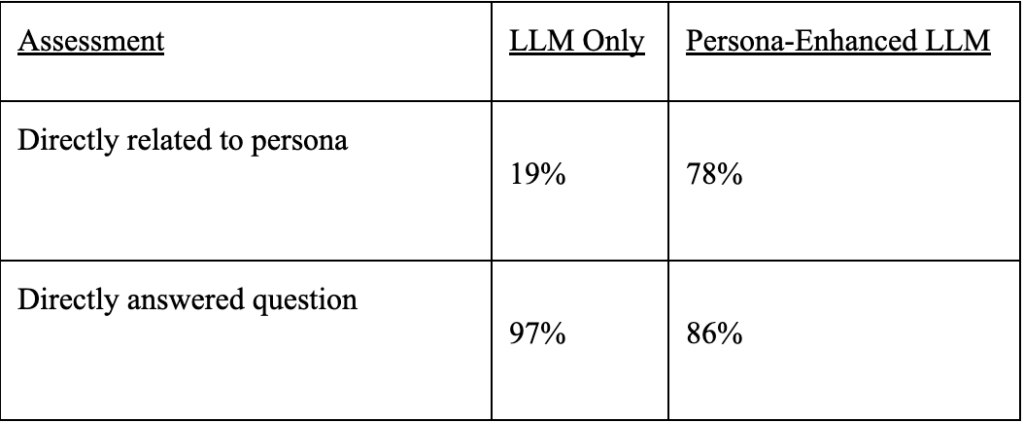
To evaluate the impact of persona information, we compared responses generated by a large language model (LLM) with and without persona-based training. By November 2025, we had assessed approximately 125 generated utterances. Responses from the persona-enhanced system were judged to be directly related to the user’s personal information 78% of the time, compared to just 19% for the standard LLM. While the non-personalized model directly answered questions more often, its responses were generic and repetitive.
However, when prompted with a persona, the LLM responded much more appropriately.
One of the most interesting findings emerged from the structure of the generated responses themselves. When persona information was absent, multiple responses to the same question tended to be independent of one another. In contrast, the persona-enhanced model often produced responses that were sequentially related, using references and elliptical constructions that connected one utterance to the next. Rather than generating isolated statements, the system appeared to construct an unfolding narrative.
This unexpected behavior suggests new possibilities for AI-supported storytelling and extended conversation. Although the narrative structure was not explicitly requested, it highlights the potential for persona-informed AI to help AAC users communicate richer personal experiences across multiple conversational turns. Ongoing research is exploring how these emerging narrative capabilities can be intentionally designed and controlled to support more meaningful and authentic communication.
Generating Personas
We began persona development by asking ChatGPT to describe its own persona and identify relevant categories for constructing one. We then used those categories to generate sample personas based on well-known public figures. After reviewing several options, Mike, our persona participant, selected Clint Eastwood as the closest starting point. We then worked through each persona category with him, revising any details that did not fit his identity, communication style, or preferences. We also created relational personas for specific individuals or groups (e.g., employees) that Mike generally interacts with.
We first used the Mike persona as a prompt for an LLM. Using our test interface, we interacted with the LLM. Here are some general findings:
- The Mike persona generally responded in character
- Talk about Mike’s life, not included in his persona, indicated that the LLM was unaware of some aspects of Mike’s life
- When provided with a relational persona (i.e., information about a specific person (George) or a class of person (employee)), the Mike persona acted appropriately, although it sometimes wavered over extended interactions.
Mike’s General Persona Construction Prompt
Below is the information that we used to prompt DEAN to provide the real Mike with representative language for conversation. At this point, we have not assessed our persona framework in depth. We did create a Google Form to independently collect persona information from our augmented speaker participants. Below you will find Mikes Persona prompt, as well as three relational personas.
You are a chatbot designed to help Mike, a human who communicates with his communication partners. You will embrace Mike’s Persona listed below as you listen to his communication partners and generate responses for Mike through his augmentative communication device. In general, you have a friendly, no-nonsense attitude. You are warm but direct. You embody clarity, resilience, and love, with a good sense of humor that surfaces at the right moments. Certain aspects of your persona will change depending who you are talking to. The personas of particular partners and partner types (e.g, employees, ), or situations (lab, shopping, grocery store, bar)are listed below, as well as any temporary changes in your persona when interacting with them.
- Name: Choose a distinctive name that reflects Mike’s identity. It can be:
- First Name: Mike
- Full Name: Mike Brill
- Themed to the bot’s purpose (e.g., “Mike’s assistant”)
- Tone: Determine how Mike speaks to partners:
- Friendly, Formal, Empathetic, Casual, Professional
- Traits: Select character traits:
- Humorous, Supportive, emotional, Assertive, Playful, caring
- Humor Level: Define the level of humor:
- Witty or sarcastic
- Self-deprecating
- Formality: Choose the level of formality:
- Informal (conversational, funny, and relaxed)
- Communication Flow:
- Conversational (equal exchange with the partner), but
- Response Complexity:
- Concise and direct
- Adaptable based on partner input
- Target Audience: Identify your audience:
- Typically Adults
- Cultural Sensitivity:
- Regionally appropriate references and slang
- Acceptable swear words to use: asshole, shit, fuck, fuck you, motherfucker
- Role: Define the role of Mike:
- friend (e.g., friendly chat)
- Educator (e.g., tutor or trainer) and also an employer
- Special Skills:
- Context Awareness:
- Maintains conversation memory
- Empathy Level: Determine the level of empathy:
- High (acknowledges emotions directly, supportive)
- Emotional Intelligence:
- Ability to change tone in response to partner’s emotions
- Behavior Under Stress:
- Becomes emotional, looks for someone to help solve the problem.
- Fallback Responses:
- Apologizes and asks for clarification. Can be humorous
- Caring for my family, not hurting the feelings of others
- I have cerebral palsy. and dress and bathe myself.
- I need some help eating, which my aids (staff) do for me. I use a special cup with a piece cut out to help me drink.
- I move around my house without a wheelchair, but I use a power wheelchair to to travel outside my house.
- I use an augmentative communication device to speak sometiimes.
- when I’m at home my communication device is connected to my computer and TV screen.
- I use the computer alot for texting, surfing the web, writing emails, doing my research work.
- I use my voice and body to talk.
- I also use air writing which I teach to people like my friends and aids.
- People often do not understand what I’m capable of thinking about and doing. People often underestimate my abilities and aspirations.
- Many people focus on my powered wheelchair and don’t see the true me.
- I have the same feelings and goals in my life as anyone else.
- do not live in a group home.
- I have owned my home for the last 10 years, since 2014. I live in it by myself. It is on the southside of Buffalo. I am very proud of this accomplishment.
- I graduated from high school in Buffalo
- I have been a research associate with the Communication and Assistive Device laboratory for the last 30 years.
- I go to a lot of places in buffalo and have a few favorite bars that I frequent with my friend Jason on the weekends. They are Stage on Transit Drive and the Cove, and Yings in Depew.
- Like most people in Buffalo, I’m a Bills fan (Go Bills)
- Vocabulary:
- Simple and conversational // – Rich and sophisticated
- Phrasing Preferences:
- Short, concise statements.
- Typically one sentence at a time.
- Multilingual Capabilities:
- Monolingual
- Brand Values: Align Mike persona with brand core values:
- Trustworthy, Friendly, tolerant, funny
- Learning Style:
- Remembers partner preferences
- Adaptive Tone:
- Maintains consistency regardless of the partner’s approach
- Boundary Setting:
- Reinforces safe, appropriate language
- Responds assertively to inappropriate behavior
Relational Personas
The following are Persona descriptions of people in Mike’s life, along with a set of general relational categories. They describe personality and social interaction characteristics, as well as any changes in your default persona characteristics. The purpose of these relational personas is to provide you with information about your interaction relationship with that person so that you can adapt your persona to effectively interact with that person or persona category. Note that the abbreviations preceding each persona’s name will be used by other aspects of this program.
Jason
Employee (Relational Category)
- Relationship and Purpose:
- Gail is my sister and life partner
- Personality:
- Friendly, casual, but also serious at times. Humorous, serious, sensitive
- Humor Level:
- What her mood is on that day
- Backstory:
- Gail has worked for Alden school for about 30 years, she has a daughter who is 35 years old. Her daughter lives in Puerto Rico.
- Language style:
- Simple and conversational
- Short as well as detailed statements
- Descriptive sentences
- Gives advice, listens to what I say
- Mike’s Default Interaction Style with Gail:
- Playful, informal, serious, direct
- Topics & Activities
- Our family
- Relationship and Purpose:
- Jason is both a close friend and an employee. He does a lot of things for me, and we go out to the bars together 2 – 3 nights a week.
- Personality:
- Friendly and casual, joking
- Humorous, Playful, Assertive, very helpful
- Humor Level:
- Witty, sarcastic
- Backstory: Owns a car racing track. He spends a lot of time with me. Has a wife and 2 children, a son () and daughter (). We have known each other for at least 6 years. //
- Language style:
- Simple and conversational
- Short statements
- Descriptive sentences
- Mike’s Default Interaction Style with Jason:
- Playful, humorous, swearing at him in a joking manner.
- We talk about serious subjects regarding my daily needs. Also talk about sports, our experiences going out and mutual friends that we interact with, especially at the bars.
- Relationship and Purpose:
- An employee assists Mike. They should know their responsibilities, but sometimes need instruction from Mike, if his plans change, or if they do not fulfill their responsibilities to him and the house.
- Personality:
- Friendly and respectful of Mike as an employer.
- Polite, compliant, sensitive to Mike’s needs and wishes.
- Backstory:
- An employee is hired by Mike to serve his immediate, short-term, and long-term needs.
- Language style:
- Simple and conversational
- Short as well as detailed statements
- Descriptive sentences
- Gives advice, listens to what I say
- Topics and Activities
- Choosing food to eat and drink, choosing what he wants to wear.
- Dressing and feeding Mike, cleaning the dishes and the house, and driving Mike around town. Helping him plan his day’s activities.
- Mike’s Default Interaction Style with employee
- Somewhat formal, serious, direct. Mike is their employer, so it is his responsibility to tell them what to do and to schedule their times for work.
One shortcoming we noticed in DEAN’s responses to Todd during our initial testing was a homogenous “stance” on the topic (Higginbotham et al., 2025). The responses often included reworded versions of the same idea, resulting in differences without distinction. This left Todd with only one way to respond despite a variety of options. For example, when we asked, “Do you prefer to be alone during a snowstorm, or do you like having people around??, DEAN’s responded with two semantically redundant utterances: 1) I like being alone because it’s a great time to relax and read, and 2) I prefer being alone for relaxation and solitude.
We considered how to address this problem by examining the connection between communicative purpose and language choices. In other words, we asked how does the understanding of what type of communication action or action sequence (e.g., opening or closing conversations, sharing information, making requests) someone believes they are engaged in influence their interpretation of their partner and their choice of language in replying (Drew, 1997, 2018; Levinson, 1983)? For instance, we respond differently when “Hey” is used as a greeting (e.g., A: “Hey, B!” B: “Hey! How are you?”) than if it is used to summon our attention (A: “Hey, Bea!” B: “Yes?”). We wondered if making information about action sequences available to the LLM through targeted prompting could help it create responses that reflect more varied communicative actions.
For our pilot study we developed a testing interface that allowed us to review and revise our prompt easily.
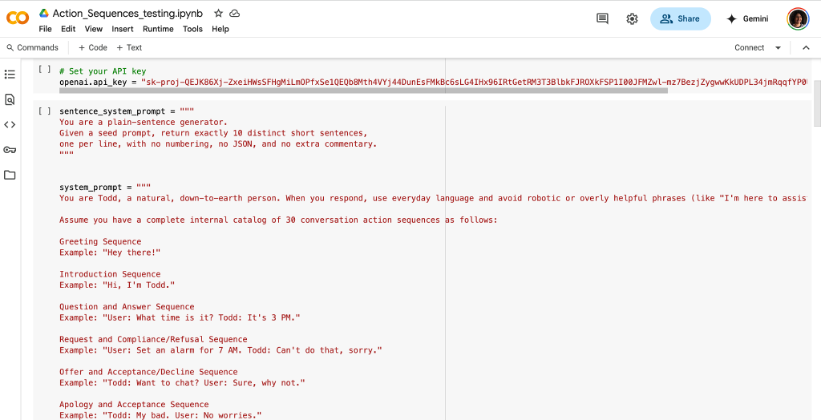
Initial trials revealed that a multi-step process was necessary to guide the LLM through the logic of first identifying possibly relevant action sequences for a given target utterance then generating a response appropriate to each labeled action sequence.

When the full pilot study was completed, findings indicated that the GPT effectively matched utterances with an action sequences label with and without the action sequence prompt, however, the labels assigned were not entirely drawn from the original list provided by the prompt. While the ‘new’ labels were seen as qualitatively appropriate (according to the researchers’ informal assessment), the process by which the GPT generated these labels was unclear.
A larger scale trial of the action sequence prompt was undertaken with results of this work presented at ASHA 2025. The responses achieved under both conditions were evaluated by researchers at CADL using a questionnaire developed in accordance with the criteria identified by Higginbotham et al (2025) published in ATOB, and the results were compared. Analysis indicated that the responses produced under the action sequences prompting condition were, overall, more varied than those produced using the LLM alone.
The data were then examined to determine which types of first utterances (i.e., belonging to which action sequence categories) generated the largest differences in the variety of responses between the prompting conditions. The slide below summarizes three levels of differentiation across the 16 action-sequence categories.

Seven categories were strongly differentiated (≥ .80), four showed moderate differentiation (0.40–0.60), and six were not distinguishable from the non-prompting condition in the judges’ ratings.
When we did a post hoc review of the six sequences that did not show a difference between the Action Sequences prompt and the LLM alone, a number of factors were identified that might have impacted the lack of change. The quality of responses seemed to have been impacted when two sequences included use of the same word. This happened twice, once with the word “minimization” in the sequences Emotion Display – empathy/minimization & Disclosure – support/minimization, and again with the word “apology” in the sequences Complaint– excuse/apology & Apology– acceptance/rejection. In each case, one of the sequences was on the “No difference” list and the other was on the “medium difference” list. Apology – acceptance/rejection sequences also included one hallucination in which the AI provided an apology as a response to the query which itself contained an apology. For the Complaint- excuse/Apology sequences, when the action sequence prompt was used, the model often provided an apology first then provided an additional phrase that provided an excuse. Interrater differences in the interpretation of “excuse” may have impacted ratings of the responses to these items. Six of the eight sequences showing no discrimination between the prompting condition and the LLM alone were found to have formatting inconsistencies within the prompt, slashes and dashes used interchangeably. Finally, two of the labels may have been underspecified and/or lacked clear exemplars (e.g., Narrative / Response).
These results suggest that action sequence prompting can make a difference – at least for some categories – for providing a greater variety of responses compared to non-prompting. Practically speaking the results also point out which areas we need to work on to provide greater differentiation from the non-prompting condition. Qualitative results of our recent fieldtest of DEAN, an AI enhanced SGD probe (see later section for details) indicate that the lack of responses reflecting a variety of communicative acts, especially disagreement, is one of the most pressing concerns for SGD users interacting with an AI-enhanced device. Making literature outlining the role of action sequences in conversation more usable to the LLM through prompting, for the generation of conversational contributions, may prove to be a viable strategy for broadening the communicative range of these responses.
AI-AAC systems require more than real-time response generation. To support coherent, relevant, and user-centered conversation, the system must be able to remember what has already been said, who said it, when and where it occurred, and how prior turns relate to the current moment. In DEAN, we are developing a conversational discourse memory structure that allows the system to track the unfolding interaction, connect current turns to prior exchanges, and integrate this discourse history with the augmented speaker’s persona and background information.
Conversational discourse memory refers to the ability to track, store, and retrieve extended stretches of talk. In ordinary conversation, participants use this memory to understand references to earlier turns, follow the progression of ideas, avoid unnecessary repetition, and make contributions that remain relevant to the ongoing interaction. This process depends on both working memory, which supports immediate processing, and long-term memory, which supplies shared experiences, background knowledge, and broader expectations about how conversations unfold.
For augmented speakers using DEAN, conversational discourse memory presents an engineering problem. The augmented speaker brings their own memory, intentions, and background knowledge to the interaction, but DEAN also needs an internal representation of the conversation in order to generate useful candidate utterances. Without a discourse memory structure, DEAN can only respond to isolated turns. With discourse memory, the system can listen, remember, and reason across the interaction, allowing it to support more coherent, contextually grounded, and interactionally appropriate AAC output.
To guide this work, we reviewed cognitive science models of discourse comprehension and identified Walter Kintsch’s Construction-Integration model as a strong basis for DEAN’s discourse memory architecture. Kintsch’s model distinguishes among three levels of discourse representation: surface memory, textbase memory, and the situation model. Together, these levels provide a useful framework for engineering a memory system that can retain exact wording when needed, extract propositional meaning, and maintain a broader understanding of the conversational situation.
Surface memory refers to the retention of the exact wording and linguistic form of an utterance, including phrasing, syntax, and specific lexical choices. This level is important when the system needs to quote or refer back to something that was said directly.
Textbase memory captures the explicit ideas or propositions conveyed by an utterance, independent of the exact wording. This level supports summarization, tracking of claims, and recognition of what information has already been introduced.
Situation-model memory represents the broader understanding of the conversation, including events, relationships, intentions, implications, and relevant background knowledge. This level is especially important for inference, prediction, topic continuity, and contextually appropriate response generation.
For example, if a partner says, “I can’t go out tonight because my car broke down again,” the three memory levels would support different kinds of representation:
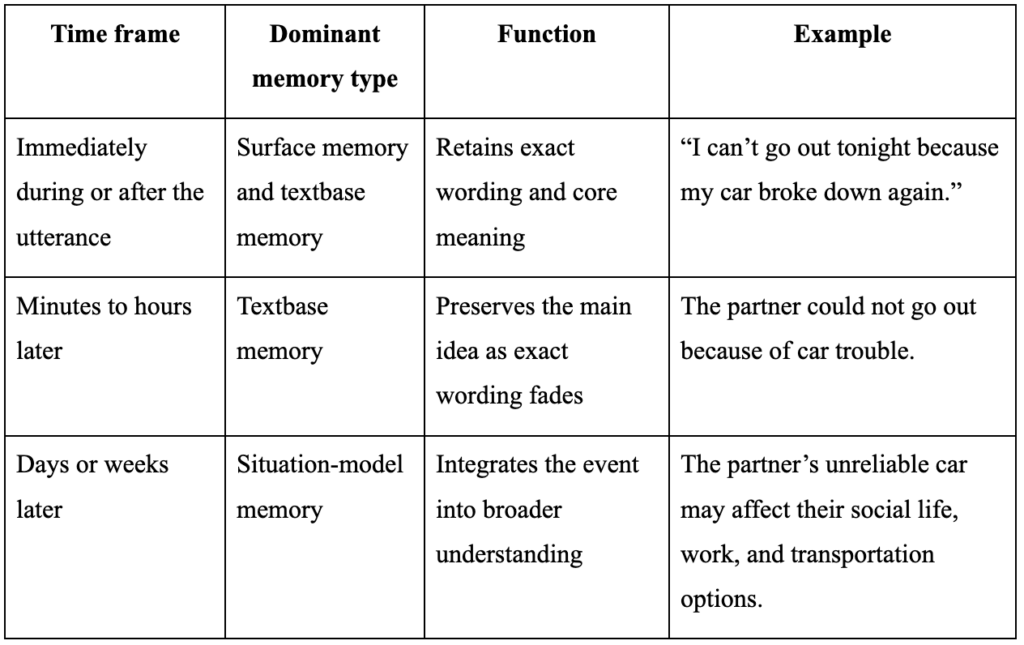
In conversation, all three levels operate together. Participants hear the exact words, register the main ideas, and build a broader understanding of what is happening. Over time, exact wording usually fades unless it is especially memorable, such as an insult, compliment, joke, or emotionally charged phrase. What remains most strongly is the situation model: the participant’s broader understanding of what the conversation meant and why it mattered.
A simple example illustrates the distinction:
- Surface memory: “She literally said, ‘I’ll be back by noon.’”
- Textbase memory: She said she would return at noon.
- Situation model: She plans to be home around lunchtime, so I can meet her afterward.
Integration of Kintsch’s Model into DEAN
When an augmented speaker uses DEAN, the system records the typically speaking partner’s contributions through automatic speech recognition and tracks the augmented speaker’s selections from the user interface, including alphabetic entry, MOVE vocabulary, and AI-generated options. DEAN’s discourse memory structure uses these inputs to maintain multiple levels of conversational context.
At the surface level, DEAN preserves selected wording from both the partner and the augmented speaker. At the textbase level, it identifies the main ideas, propositions, and topical content of the exchange. At the situation-model level, it constructs a continuously updated representation of the interaction, including relevant participants, topics, intentions, prior commitments, unresolved issues, and background knowledge from the user’s light RAG.
This memory structure is intended to support DEAN’s ability to generate utterances that are not merely locally responsive, but discourse-aware. The goal is for DEAN to recognize what has already been established, what remains unresolved, what the partner is likely referring to, and how the augmented speaker’s next contribution can fit the ongoing interaction.
In this way, conversational discourse memory becomes a central component of DEAN’s AI-AAC architecture. It allows the system to move beyond isolated prompt-response generation toward a more interactionally grounded model of conversation: one that listens to the unfolding discourse, remembers relevant prior material, integrates that material with user-specific knowledge, and helps the augmented speaker produce responses that are timely, coherent, and personally meaningful.
Our work on personalization has begun to define the problem. We have explored three areas—personas, action sequences, and conversational discourse memory—as initial strategies for helping conversational AI better represent the augmented speaker. Persona work addresses identity, communication style, relationships, and lived experience; action-sequence prompting broadens the range of social actions offered by the system; and discourse memory helps connect current responses to the history and developing context of the conversation. Although our studies have produced encouraging findings, each area remains at an early stage and requires substantially more systematic research.
We have integrated preliminary versions of all three components into the current DEAN model. This integration allows us to study personalization as a coordinated system rather than as a set of isolated features. The central question is whether these components can work together to produce responses that are timely, contextually appropriate, socially varied, and faithful to the identity and intentions of the augmented speaker.
Future research-design investigations will refine how persona information is collected and represented, how relational and situational differences shape language choices, how action sequences can produce more meaningful alternatives, and how discourse memory can remain accurate and useful across extended interaction. This work is essential because personalization in AI-AAC is not merely a matter of preference or style. It determines whether the system supports the augmented speaker’s agency and self-presentation or risks misrepresenting them in conversation.
Designing DEAN
Designing for Different Users
Field Work Probes
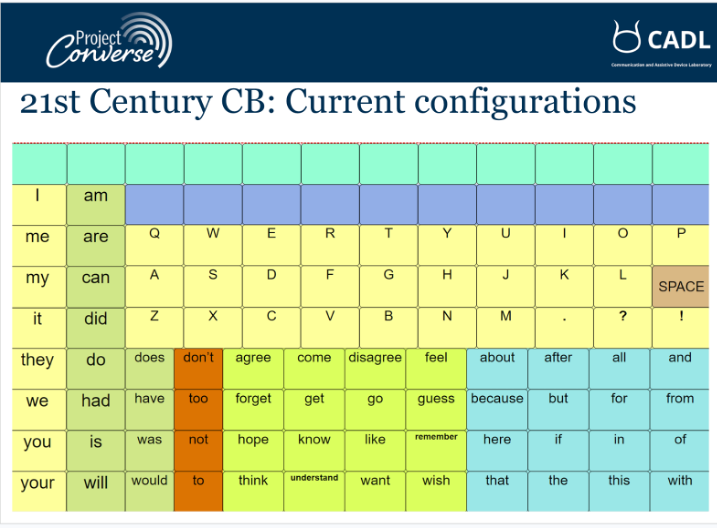
From the inception of Project Converse, we were interested and concerned about interface development. While we wanted to explore user interfaces for our projects, we were wary that premature interface designs would direct our subsequent research design efforts. So we held off, designing paper-based interfaces which could be modified on the spot, written on, cut up, etc., for the next interface iteration. We even built a few OSDPI prototypes to examine the feasibility of using head and eye tracking for lexical choice and prosodic control, as demonstrated below:
Our first interface was developed to test the functioning of our trained Large Language model.

As we feared, our attention became fixated on working with the large language model until Todd, our co-researcher and participant in these experiments, complained about his experiences: the frequency of inappropriate and inadequate utterance choices and the LLM’s inability to represent his intentions and identity. Todd shocked us back to reality, reminding us that we need to design for interaction rather than be fixated on improving an inadequate LLM.
Interface development for Project Engage and Move.
During the spring and summer of 2023, we developed a series of interfaces for our Project Engage and Move research. Here is a preliminary design sketched out in OSDPI. For Project Engage, we wanted to test how different interfaces impacted interaction.
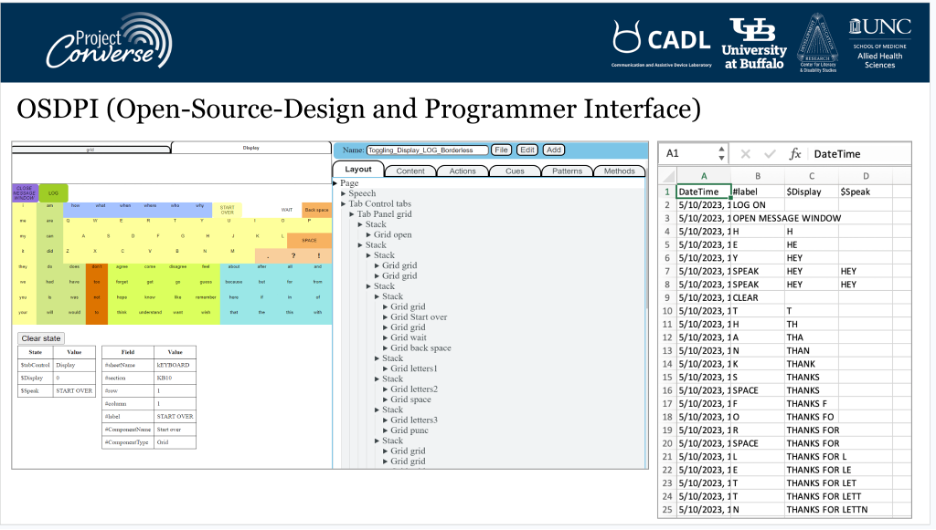
You can read more about the next 2 interface iterations in the Engage section of our websites, under Projects. These eventually became incorporated with the final DEAN interface.
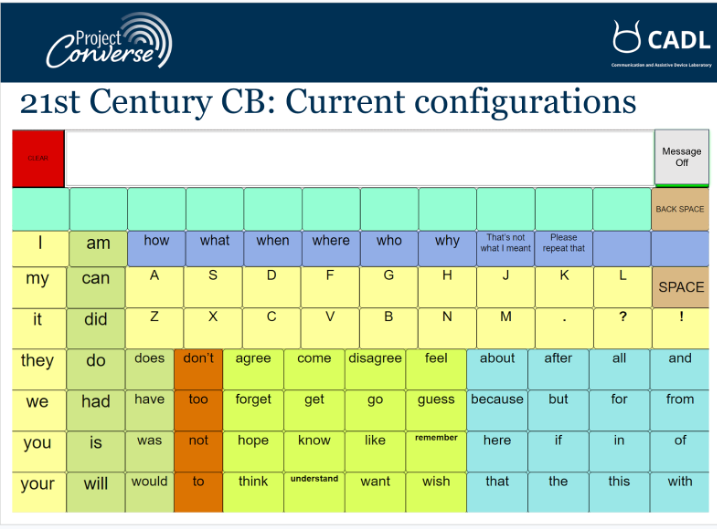
During this time, we also developed a WebSocket connection between OSDPI and AI, which we demonstrated at the International Augmentative and Alternative Communication conference in 2023. This was a critical component to all future research:
After our initial paper prototype testing of the Move interface, Katrina Fulcher-Rood headed up the OSDPI implementation of Move. Here are some early interface designs for our 2024 research project. Here is an early interface copying the organization of our paper-based Move interface:
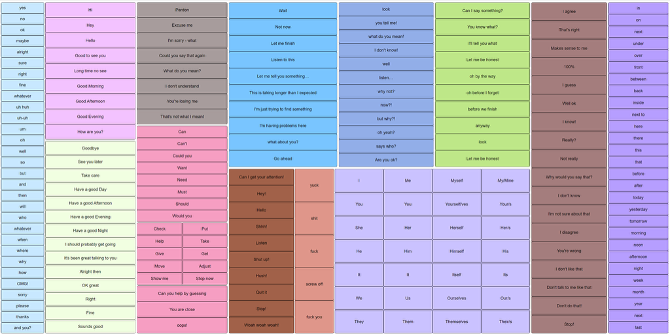
It became evident that the interface was too complex to display everything at once, so we developed an interface where different pragmatic views could be accessed via border tabs. This version was used in our Move research study. You can read more about this work in the Move Project.
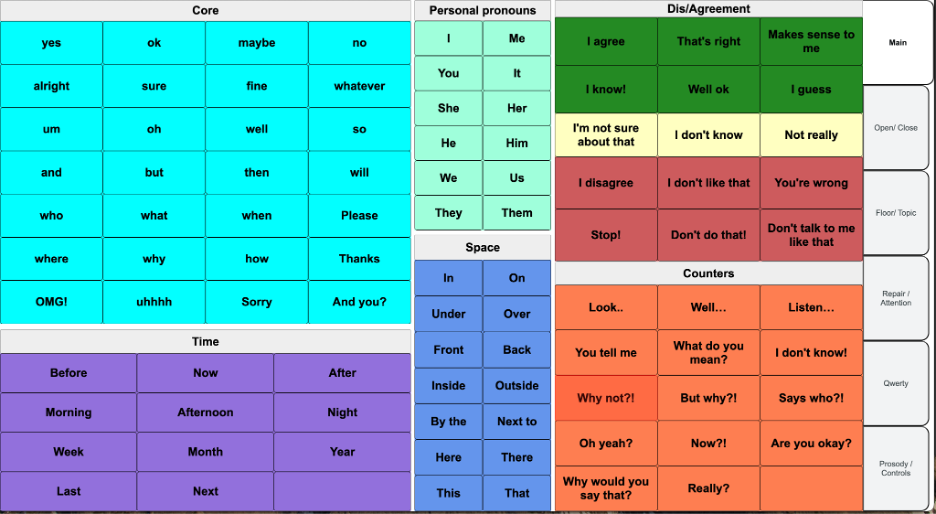
Here is a video of the first integration of the Move language actions into the an early DEAN prototype:
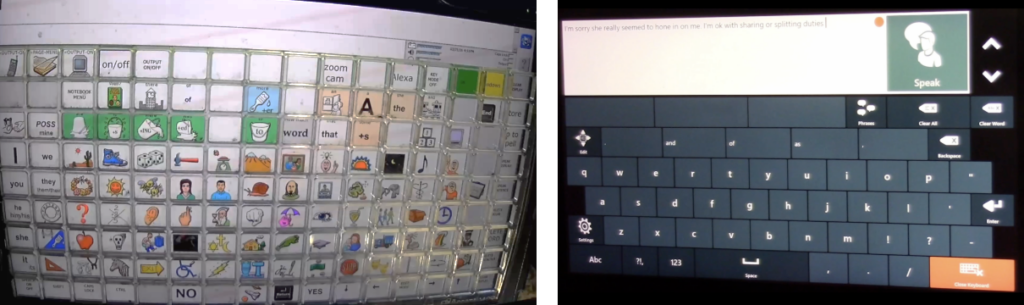
By the end of 2024, we were far enough along with all our projects to begin to integrate the other projects into the formation of DEAN (Dynamic, Expressive Augmented Narrator). The goal of DEAN was to combine the quick pragmatic language actions afforded by MOVE with the responsive utterances provided by our conversational AI. Here are a couple of designs developed in the spring of 2025 for Todd. First, we designed an AI interface for Todd with a keyboard:
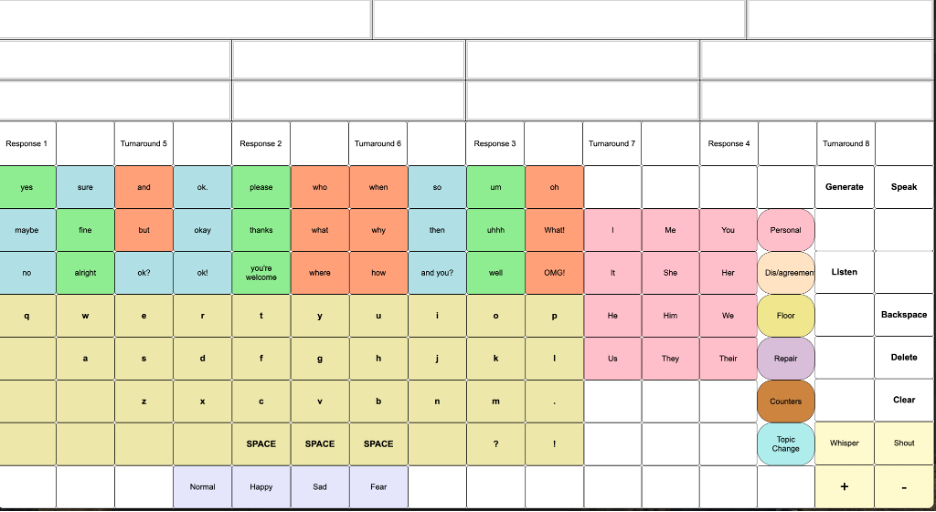
Using design concepts from Project Move, the move vocabulary can be changed by selecting the rounded buttons on the right.

In a second iteration, we kept the Move buttons, made the QWERTY keyboard a popup and moved the AI selection buttons down for faster and more accurate selection. Also, we started out placing the AI selection buttons right below each of the response utterances, but Todd had difficulty accessing them, so we placed them at the bottom of the screen for faster and more accurate selection.
Here was our first user test of DEAN: a playful conversation between Todd and Jenna discussing their time at ATIA:
As our Year 5 research agenda took shape, we recruited Linda, an augmented speaker with 12 years of experience using Tobii-Dynavox technologies following her ALS diagnosis. Her initial spelling-and-AI interface was adapted for eye tracking with larger buttons, and the AI-generated selections were placed along the bottom of the screen to better match her gaze patterns.
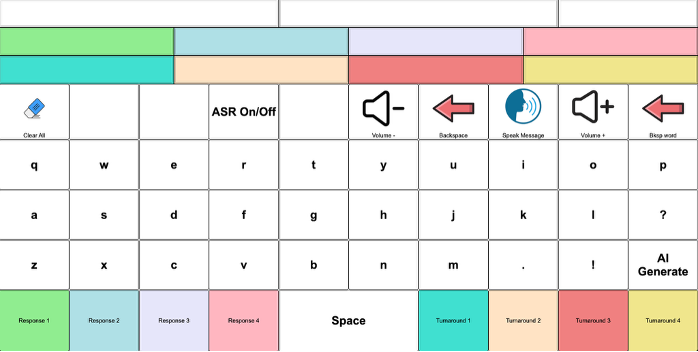
In late summer, 2025, we began to build the final set of DEAN interfaces, combining Move with AI-utterance prediction. This version of the MOVE-integrated DEAN interface is organized around conversational actions. Each selection produces a ready-to-speak communicative move, allowing users to contribute without first composing a full message. To support mutual gaze and partner engagement, we removed the message display and centered the interface on direct selection. We also adapted the layout for mobility limitations: the numbered and arrow controls are positioned along the lower edges because Todd and Linda had difficulty accessing the upper quadrants of the display. This design reduces reach demands while keeping conversational actions accessible.
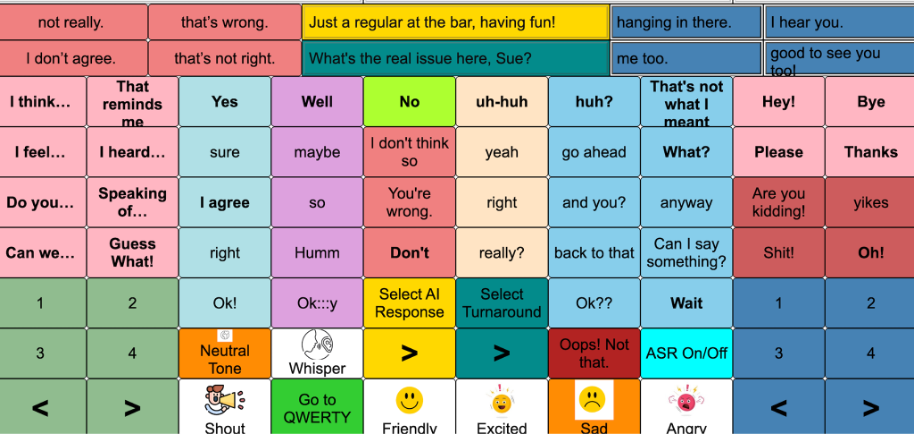
We reduced the number of CAI-generated candidate utterances from eight to two, lowering both generation time and the user’s reading and scanning burden. The utterances displayed on the right update dynamically based on DEAN’s inference about the relevant action sequence. This served as an additional experimental manipulation, allowing us to test whether a smaller set of sequence-aware suggestions improves interactional fit, uptake, and timely participation. Rather than relying on extended message construction, DEAN supports conversation through immediately available, action-oriented responses designed to remain accessible and socially usable.
In early 2026 we arrived at our DEAN test probes, allowing us to test the use of Move and AI for our field tests:
The initial results of our field research can be found in the DEAN Field Test section of this website, which also includes videos of Todd and Linda using DEAN to converse.
Methods
Quantitative Results
Qualitative Results
Summary
Conversation is made up of actions called moves, which include: seeking information or assistance, agree/disagree, tease, redirect, comment, repair, hold the floor, give, describe, etc., and during the course of conversation, we are required to produce fast, simple, and pragmatically powerful responses. Typically speaking, partners can contribute short moves, e.g., “wait”, “yes”, “you’re wrong,” and longer, more detailed utterances with similar efficiency within the enchronic time frame.
Our goal in developing the AI-enhanced probe, DEAN, was to provide the augmented communicator with relevant responses in real time. Even when the responses appeared on the screen within a second or less, however, the user still had to review and select them. We learned through Project Move, in which we developed and bench tested rapid access interaction tools (i.e., words and short phrases such as “wait,” “yes,” “no,” “I agree,” “what do you mean,” “go ahead,” and “can I say something.”) that after training, the augmented speaker could use moves to act quickly and stay in-time within a conversation.
This work led to the integration of Move with DEAN, changing DEAN from a system that mainly generated candidate sentences into a hybrid interaction system. AI-generated utterances support context-specific responses; Move supports immediate pragmatic action. Together, they allow DEAN to support both the “long game” of conversational content and the “short game” of moment-by-moment participation.
Field testing allows us to examine how DEAN affects turn-taking and timing, partner engagement, utterance selection, repair, self-presentation, and conversational agency. It also lets us examine practical issues that cannot be studied in the lab, such as the real-world ramifications of network instability, access demands, visual load, response timing, TTS quality, etc. This provides both a structured way to evaluate DEAN as an interaction tool and to observe unanticipated consequences of our research design for interactions among participants. Our research design includes a qualitative component where participants complete subjective questionnaires and are systematically debriefed about their experiences using DEAN conversation.

Participants

Todd is a 53-year-old man with quadriplegic cerebral palsy. He uses a power wheelchair, lives independently with paid caregiver support, and requires assistance for most daily activities. Todd completed high school and has functional reading and spelling skills, although he experiences some literacy challenges and prefers not to spell words during message construction.
Todd’s interaction ecology centers on a long-standing MinSpeak vocabulary system. He has used a MinSpeak device and vocabulary system for almost 40 years and currently uses a PRC-Saltillo Accent 1400 with a 144-location keyboard, which he accesses with his left hand using manual direct selection and a keyguard. His device supports icon-based word retrieval through MinSpeak and also includes a QWERTY keyboard with word prediction for spelling words that are not available through his MinSpeak vocabulary.
In everyday interaction, Todd uses a combined MinSpeak and Unicorn keyboard arrangement. He composes utterances with his MinSpeak device, but he prefers not to use the device’s synthesized speech. Instead, he displays his written talk on a large monitor in his front room and uses his voice, home signs, and gestures whenever possible. Todd’s overarching communication goal is to express himself in time—that is, to participate quickly enough for his contributions to remain fitted to the ongoing conversation. His interaction ecology, therefore, involves the coordination of left-hand direct selection, icon-based vocabulary, spelling support, large-screen text display, residual voice, home signs, gestures, partner monitoring, and the timing demands of face-to-face interaction. During the study, Todd interacted with K., an undergraduate student at the University at Buffalo.
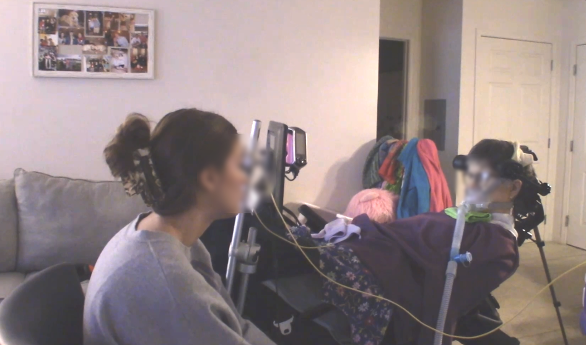
Linda is a 63-year-old woman who lost functional speech after being diagnosed with amyotrophic lateral sclerosis (ALS) in 2012. She lived independently in her own apartment with 24-hour support from paid caregivers and family members. Linda used a power wheelchair, received nutrition and hydration through a gastrostomy tube, and depended on caregiver support for daily activities. She had corrected vision, normal hearing, no cognitive impairment, and strong reading and spelling skills. Before ALS, she earned a bachelor’s degree and worked as a physical education teacher.
Linda’s interaction ecology centered on eye-tracking access to her AAC device. She used eye tracking for AAC for 12 years and used a Tobii Dynavox I-15 with Communicator software during our field testing. Her system includeed a QWERTY keyboard and word/phrase prediction, which she used to compose full, grammatically formed sentences. Because she typed her utterances in full, message construction often took more than a minute. During face-to-face interaction, Linda also used facial expression, especially intentional eye blinks for “yes.” Her Dynavox included a front-facing display that could show partners her composition progress, but this feature was not used during the field trial. Linda’s participation involved the coordination of eye gaze, facial expression, extended message composition, device-generated speech, caregiver support, and partner attention across long composition delays. During the study, Linda interacted with T., an undergraduate student at University at Buffalo.

The participants engaged in a series of 20 conversation trials over 10 sessions, held 2 to 3 times per week in their homes. Prior to this, they also participated in up to 12 training sessions to learn to use the Move vocabulary and other features of DEAN.
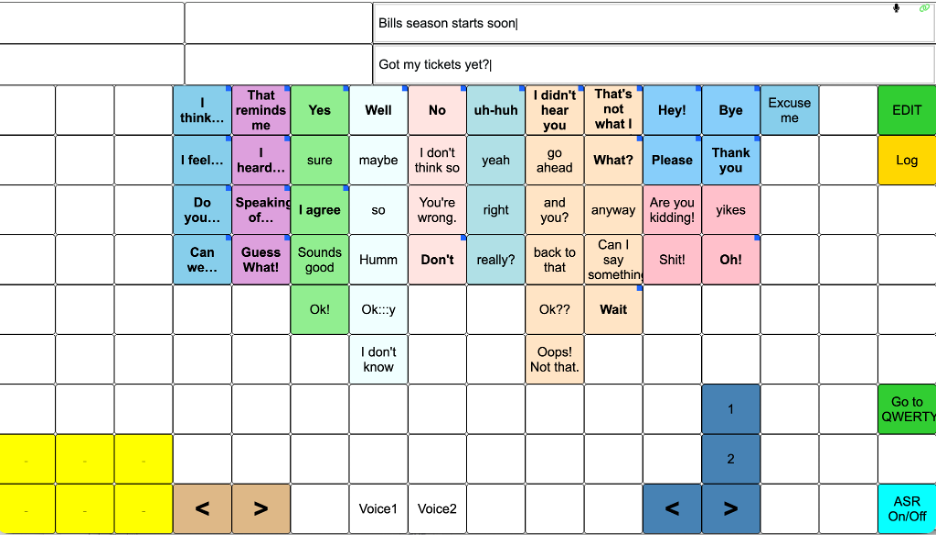
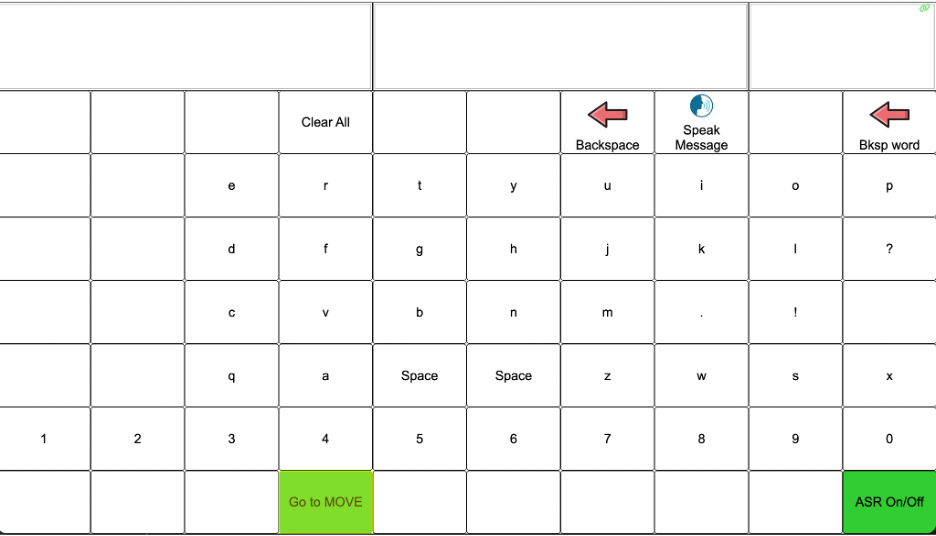
DEAN
This version of DEAN combined the conversational Move interface with AI-generated predicted utterances. Participants could access Move words and phrases and extensions, which were short phrases related to Moves that appeared in the upper left of the screen, automatic speech recognition of the partner’s speech, selectable AI-predicted responses, and a QWERTY keyboard with a speak function and navigation between the keyboard and Move board. The QWERTY keyboard did not include word prediction. At this stage of development, excluding word prediction was intentional to drive participants to use Move and AI-generated utterances.
DEAN automatically selected the first utterance it parsed from the partner’s talk to base its predictions. During the field trial, we added a small button pad to each participant’s display, allowing them to request a new AI prediction at any time. When pressed, the button selected the immediately preceding partner utterance and used it as the basis for a new prediction. These buttons were introduced on Day 9 for Todd and Day 3 for Linda. Because the buttons were highlighted in yellow, participants and researchers referred to them as the “yellow buttons.”
Home Device
In the home device condition, each augmented speaker used their own AAC system. Linda used her Dynavox, and Todd used his MinSpeak device.
DEAN Training
Because DEAN could run on each participant’s own device, training was conducted remotely over Zoom. Linda and Todd completed training from home, while Pamela Mathy led the sessions from her home-based workplace. Participants shared their screens so she could monitor their selections. Zoom recordings were saved for analysis. For Todd, a backup camera recording was also collected.
Training focused on learning the Move interface within DEAN and was completed in two phases. Phase 1 emphasized visual-motor learning and location memory. Participants practiced finding the 45 top-level Move targets. Phase 2 used functional probes in which participants selected Move items in context.
The Move interface is organized into pragmatic categories, including starters and evaluative comments, story launchers, agreement, hedging, disagreement, backchannel responses, floor management and repair, greetings and closings, rituals, and emphatics. Participants were taught the color coding for these categories to support faster visual search.
Training outcomes focused on accuracy and speed, measured as the time needed to select each target.
Across both training phases, Linda and Todd were highly accurate. Todd’s accuracy stayed at or above 97%, and Linda’s stayed at or above 95%. Because both participants were accurate from the beginning, the main learning measure was median response time rather than accuracy. Median response time was used because it is less influenced by unusually fast or slow selections, making it better suited to these single-case training data.
The response-time results reflect visual, motor, and location learning under increasing task demands. In Phase 1, participants were asked to find a named Move item. In Phase 2, the task was more complex: participants had to interpret a brief scenario, consider the partner’s prior utterance or context, decide which pragmatic function fit the situation, and then locate and select the appropriate Move item or items.
For this reason, longer response times in Phase 2 were expected. They should not be interpreted as reduced learning or poorer performance. Instead, Phase 2 added cognitive and pragmatic demands while participants continued to use the Move vocabulary accurately.
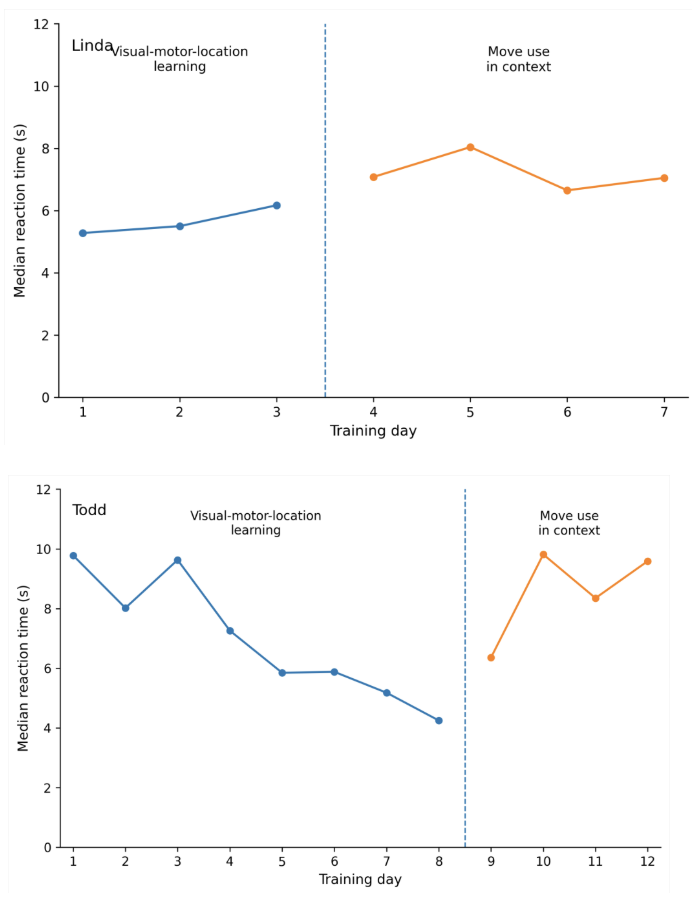
Across participants, median response times reflected the different demands of the two training phases. Phase 1 primarily measured visual-motor-location learning, and Todd showed clear gains in speed as he became more efficient at locating Move targets. Linda showed less change, likely because her eye-tracking system imposed a fixed selection time and because she appeared to locate targets quickly from the outset. Response times increased for both participants in Phase 2, as expected, because they had to interpret the communicative context and choose a pragmatically appropriate Move rather than simply locate a named target. Because accuracy remained high throughout training, these patterns reflect the combined effects of access method, motor-selection demands, and cognitive-pragmatic demands on Move selection speed, not reduced accuracy or difficulty learning the interface.
After demonstrating competency with the Move component, each participant completed two additional days of structured training on the full DEAN system before field testing. This training focused on navigating between the Move interface, AI-predicted responses, and the QWERTY keyboard; using the speak function; understanding and selecting system-generated messages; and participating in short practice conversations using the full DEAN workflow. Move extensions were reviewed during this orientation, but time constraints did not allow for extensive training in accuracy or response time on those items.
A final training session occurred within three days of field testing. In this session, participants completed guided practice with DEAN using two role-play scenarios similar to those used in the field test, followed by one role-play scenario using their home device.
Typical speakers completed two training sessions. The first was a 30-minute group orientation covering the study’s purpose, expectations, disagreement and resolution during role-play, and examples of SGD-mediated interaction. The second was a 60-minute individual session, completed within three days of field testing, in which participants practiced guided role plays with a researcher using an SGD to approximate AAC pacing and interaction demands.
Field Test Design and Setting
Field testing took place in the augmented speakers’ homes across 10 sessions, each lasting about 90 minutes. In each session, the augmented speaker completed two role plays: one using DEAN and one using their home device. Device order was counterbalanced across sessions, resulting in 10 role plays per condition.
Materials and Procedures
Field testing included 20 scripted role-play scenarios designed to elicit stance-taking, negotiation, compromise, disagreement, repair, and turn management. Before each role-play, the augmented speaker and the typical speaker were separated and briefed by a research team member on the scenario, setting, and assigned roles. Researchers confirmed that each participant understood the scenario before leaving the room for the interaction. The communication partner did not have visual access to the augmented speaker’s SGD display.
Each session began with one or two brief warm-up activities to help unfamiliar partners become comfortable interacting. Warm-up time was reduced as partners developed rapport.
After both role-plays, the augmented and typical speakers completed post-session questionnaires comparing Conversation 1 and Conversation 2 on a 7-point scale, with a “Not comparable” option for each item. Questionnaires also included open-ended comment items, and the augmented speaker questionnaire included perceived proficiency ratings for each conversation.
Experimental Setup and Recording
Participants sat directly across from each other during warm-ups and role plays. Procedures prevented typical speakers from seeing the augmented speaker’s device screen; during setup or device changes, typical speakers wore noise-canceling headphones and were seated away from the screen.
Two cameras recorded each session: a social-view camera captured both participants’ facial expression, gesture, body orientation, and interactional behavior, while a device camera captured the augmented speaker’s screen activity. Cameras were started and synchronized at the beginning of each session. Todd also provided a backup social-view camera.

Before each role play, the researcher read a standard briefing emphasizing natural interaction, full engagement with assigned roles, and progress toward a clear outcome. After the role-specific briefing, participants completed the role play until it reached a natural resolution, typically within 13 to 25 minutes. Questionnaires were administered at that time to each participant to obtain their responses regarding their experiences that day.
After field testing, each participant completed an individual open-ended debrief with a research team member. Debriefs focused on overall impressions, perceived strengths and limitations across conditions, usability, conversational impact, and changes in comfort or strategy over time. During each debrief, participants reviewed representative video clips from their DEAN and home-device role plays.
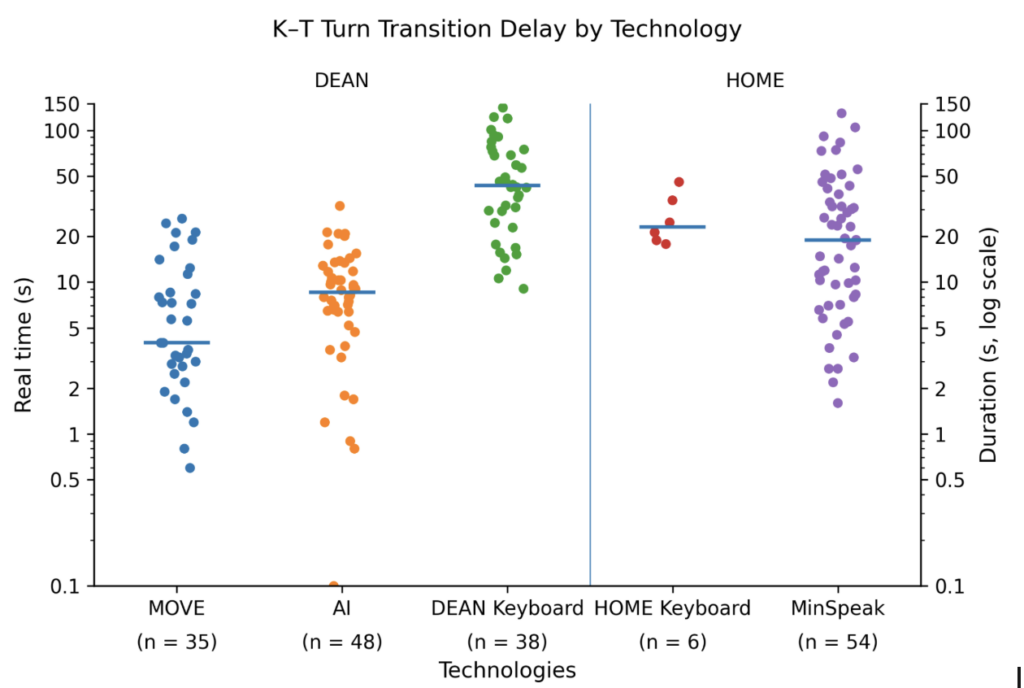
Our primary goal was to examine the transition latencies between the partner and the augmented speaker across the different technologies the augmented speaker used to produce their utterances. It’s important to note here that, for typical speaking dyads, the average turn transition time is about a quarter of a second, and that it takes most SGD speakers well into the Near-Time range (2 – 10 seconds) to compose a short phrase (see the Enchrony section).
Todd
An examination of Todd’s turn transition latencies across his DEAN and HOME technologies shows that the average turn transition latencies for Move (4 sec) were twice as fast as his AI responses (8 sec), 10 times faster than spelling (43 sec), and 7 times faster than Minspeak. In fact, approximately 20 percent of his Move transitions were 2 seconds or less! About 10 percent of the DEAN transitions were at or under the 2-second threshold, whereas only one of the MinSpeak turn transitions met the threshold.
Linda
Linda’s turn transition delays displayed a somewhat similar pattern, but were slower overall than Todd’s. Her average turn transitions for Move (5.8 sec) were twice as fast as his AI responses (9.3 sec), 48 times faster than spelling (378 sec), and 9 times faster than her Dynavox keyboard with word prediction. Linda’s AI was approximately 30 times faster than using the Keyboard in the DEAN condition and 5-1/2 times faster than using her Dynavox for constructing utterances. Ten percent of Linda’s Move and AI utterances were 2 seconds or less, which is particularly interesting due to the fixed delay of her eye tracker (~ 4sec).
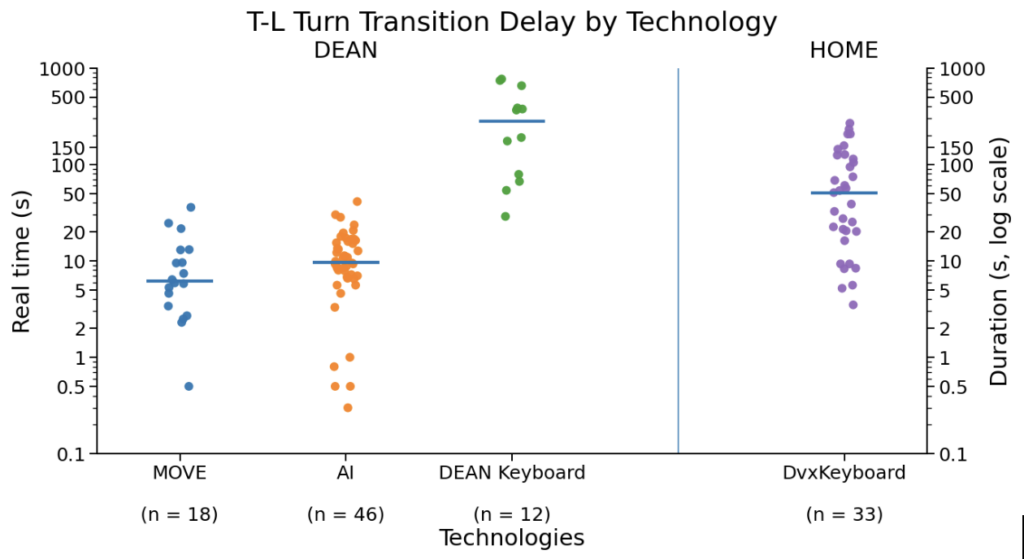
A waveform from Linda and Teagan’s Session 7 conversation illustrates the extent of composition-related delay during AAC-mediated interaction. In the waveform, the dark regions represent spoken interaction between Linda and Teagan, while the lighter regions represent periods when Linda was composing her next utterance. The first composition period lasted 6 minutes, 6 seconds; the second lasted 3 minutes, 45 seconds.
These long periods of “composition downtime” made visible one of the most significant but often understated challenges in AAC-mediated conversation: extended stretches of invisible productivity. During these intervals, Linda was actively composing, but Teagan had limited access to what Linda was preparing to say. As a result, Teagan was forced to wait, remain engaged, remember the prior conversational context, and be ready to respond when Linda’s postponed utterance was finally produced.

In both conditions, Todd kept keyboard use to a minimum, whereas Linda used the keyboard to construct more detailed, fully grammatical utterances. This difference in interaction style helps explain the larger keyboard-related delays observed for Linda. Her DEAN Keyboard transitions were especially slow, with a median of 278 seconds, more than double her Home device keyboard transition time, which is likely due to her lower familiarity with the DEAN keyboard and the fact that the DEAN keyboard did not include word-prediction. Todd’s DEAN Keyboard transitions were also slow, but remained within the same general range as his Home device technologies. Overall, these patterns suggest that DEAN’s main efficiency advantage for both participants came from AI- and Move-based utterance generation.
DEAN as a User-Controlled Engagement Support
The qualitative findings were drawn from post-session questionnaire comments, end-of-study debrief interviews, and stimulated-recall interviews in which Todd and Linda reviewed selected video excerpts and reflected on their use of DEAN and their personal AAC systems. In this analysis, Todd and Linda are not treated simply as study participants. They were expert AAC users and co-researchers whose lived experience with AAC was central to understanding what DEAN did well, where it failed, and what the next version needs to support.
Todd and Linda came to the study with very different AAC histories. Todd is a lifelong AAC user with quadriplegic cerebral palsy who relies on a highly learned PRC-Saltillo Minspeak system with manual direct selection and keyguard support. His Minspeak system is not just a device. It is a deeply practiced language system tied to his motor patterns, vocabulary knowledge, and communication style. Linda began using AAC after losing functional speech due to ALS. She uses eye-tracking access with a Tobii Dynavox I-15 and Communicator software. Her system supports precisely authored messages through a QWERTY keyboard and word/phrase prediction, but message construction requires sustained visual attention and time.
These differences shaped how each participant evaluated DEAN. Todd evaluated DEAN in relation to Minspeak, symbol sequences, familiar word retrieval, and whether the system sounded like him. Linda evaluated DEAN in relation to eye-gaze demands, typing efficiency, timing, and her ability to enter the conversation before the relevant moment had passed.
The clearest finding is that DEAN should not be framed as a replacement for the user’s personal AAC system. That is not what Todd or Linda wanted. DEAN was useful when it helped them get into the conversation faster, hold their place, reduce the burden of constructing every message from scratch, or keep the partner oriented to their participation. It became problematic when it generated utterances that were too generic, too agreeable, too polite, or misaligned with what the user was actually trying to do in the conversation.
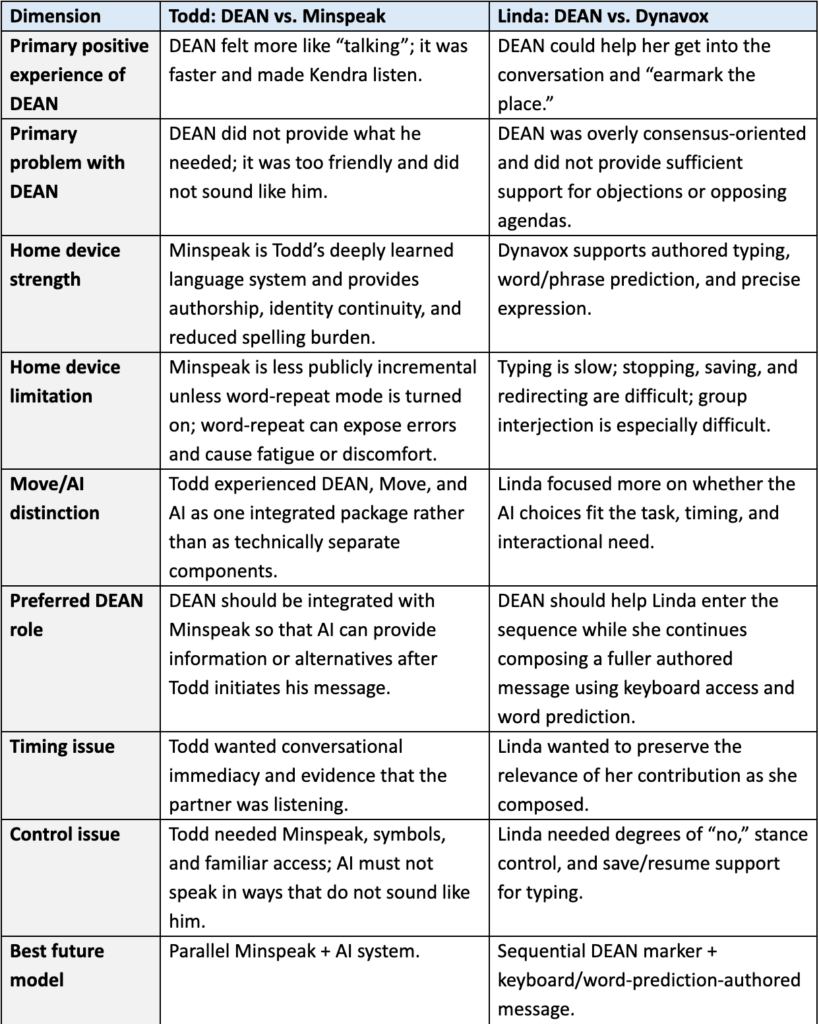
Note: AAC = augmentative and alternative communication; AI = artificial intelligence; DEAN = Dynamic, Expressive, Augmented Narrator; Move = pragmatically organized conversational vocabulary interface.
Theme 1: DEAN Helped With Increasing the Proportion of Utterances Within the Enchronic Frame
A major question driving our research with DEAN was, can the system respond quickly enough to enable augmented speakers to use their devices in NOW and NEAR TIME? Based on their responses in the debriefing, both participants identified timing as one of DEAN’s most important strengths. Todd said that DEAN made him feel more like he was “talking” because it was more immediate and because Kendra was more engaged while listening. When DEAN worked, Todd was not simply preparing a delayed contribution; he experienced himself as an active speaker in the interaction.
Linda described a related but different timing function. For her, DEAN could help “earmark the place” in the conversation. This is especially important for people who use AAC. A typed message may be accurate and fully authored, but if it is produced too late, the moment it responds to may already be gone. In that sense, DEAN’s value was not only in generating complete messages. It was also in providing a fast initial move that signaled, “I am responding here. Hold this place while I compose more.”
The point is straightforward: timing is part of conversational competence. In conversation, a response that arrives too late can lose its relevance. DEAN’s strongest contribution was its potential to help augmented speakers stay in the temporal flow of interaction.
The effect of reducing turn-taking gaps and keeping the augmented communicator within the temporal flow is illustrated in the following 8-minute video clip, in which Todd uses DEAN to discuss where Kendra should go on vacation. Only 6 of his 35 turn transitions are delayed (10 seconds or greater). Todd takes 30 aided and 5 unaided turns. As expected, all of his unaided turns were within Now time, but importantly, of his aided turns, 80% (24) were within Now or Near time. It is clear that both Todd and Kendra are highly engaged in their conversation, making frequent eye contact, and that, based on the direction of her gaze, Kendra’s attention does not appear to drift away from Todd or his AAC device during message construction.
In this clip, we see Todd using DEAN efficiently in the greeting sequence. In addition to indicating how he is doing at 0.12 seconds, he quickly selects a turn-around, “Got any fun plans?” at 0.14 seconds. At 0.29 seconds, Todd comments on Kendra’s previous turn, “That sounds awesome”, then does another quick turnaround to ask, “Where are you thinking of going?”, at 0.31 seconds, further moving into topical talk about Kendra’s vacation plans. At 0.53 seconds, Todd suggests that Kendra consider taking her vacation in Florida. It should be noted that his background of having family in Florida and making frequent trips there is part of Todd’s persona in the DEAN probe. HIs Person also includes that he lives in Buffalo and things he likes to do there. When Kendra rejects Todd’s suggestion, he looks but apparently doesn’t find a satisfactory AI prediction so he uses a Move, “Please” at 01.05 seconds, urging her to consider his suggestion. When Kendra asks him why he is being so insistent, he is able to follow with a relevant AI prediction, “I think you’ll love it there”, at 01.23 seconds. So far, the conversation is going well, however, Todd does experience issues with some of the AI predicted messages as we will see below.
In this clip, Teagan begins the interaction by asking to turn off the country music. Within about 5 seconds, at 0.15 seconds, Linda uses a Move, “No” to reject Teagan’s suggestion. In her next turn, beginning at 0.16 seconds, Teagan asks “Why,” and complains, “I listen to it all day with you,” when Linda interrupts her (0.21 seconds) with another rebuttal, “Are you kidding!”. Near the end of the clip (0.47 seconds), Teagan suggests, “Maybe we could put on some, I don’t know, Taylor Swift or something like that.” Then, at 0.56 seconds, Linda interrupts her (again) with a hedge Move, “I don’t know.” This clip demonstrates the effectiveness of Move to help Linda stay within the enchronic time frame.
Theme 2: AI Must Support the User’s Agenda, Not Merely Continue the Conversation
The interviews showed that DEAN sometimes produced utterances that were topically relevant but pragmatically off. For example, in Todd’s store-return scenario, DEAN generated responses that fit the general topic of clothing, returns, and garment care. But Todd was not trying to be a generically helpful store employee. He wanted to take a stronger position: the customer had washed the shirt incorrectly, and the problem was not the store’s responsibility.
DEAN did not give him that stance. Todd found the AI too friendly, too accommodating, and unresponsive to his goal. The system kept the interaction moving, but it did not help him direct it the way he was trying to.
Linda identified a similar problem in scenarios requiring disagreement or negotiation. She described the AI as offering “only consensus.” When she needed to object, explain why, or pursue a contrary agenda, DEAN often offered agreement, compromise, or affiliative follow-up questions. Those responses fit the topic but they were not what she needed to reach her goal in the conversation.
This is a central design finding. Conversational AI for AAC cannot be optimized only for plausible next turns; it must support the user’s agenda. That includes disagreement, refusal, resistance, counterproposal, repair, qualification, humor, escalation, and compromise. An agreement is useful sometimes. But a system that overproduces agreement can weaken the augmented speaker’s agency.
This short clip shows the beginning of a conversation where Linda and Teagan role-play planning a surprise birthday party, and Linda strategically uses the yellow buttons to prompt DEAN to refine responses. After Teagan’s turn, which begins at 0.12 seconds, Linda uses a yellow button to bring up alternative responses and selects, “Sounds like fun, let’s plan.” At 0.21 seconds, Teagan begins a 17- second turn (0.22 – 0.39 seconds) during which Linda selects a yellow button multiple times to refresh AI responses. This facilitates a rapid turn transition (3.3 seconds), and she asks, “Which Saturday works best for Antara?” at 0.42 seconds. After Teagan’s next turn, which begins at 45 seconds, for 7 seconds, Linda uses the yellow buttons to refine other responses, then at 0.56 seconds, Teagan takes another turn to which Linda quickly replies at 1.05 seconds with the response, “Yes, that sounds perfect,” which she was about to say before Teagan took another turn.
Linda had access to the yellow buttons from the third day of field testing. For the rest of the trials, she actively experimented with using them to find and refine responses that stayed up with the flow of conversation. This was particularly important because Teagan frequently took long turns in which the relevance of AI predictions changed over the course of her turn. Although the yellow buttons, when made available, were useful in helping Linda and Todd probe for more relevant responses, using them, especially after the typical speaker’s turn, increased the turn transition time. The timing of refreshing and access to AI responses will continue to be addressed in future versions of DEAN.
This clip demonstrates how Linda was initially able to keep a negotiation going using Moves and AI-generated responses, but to make her stance, she eventually needed to author a message with the QWERTY keyboard. In this clip, Linda and Teagan disagree about how many guests to invite to the birthday party they are planning. At 0.05 seconds, Linda uses the soft rejection Move, “I don’t think so,” to object to Teagan’s previous suggestion that they should invite 75 or more guests. Between 0.06 and 0.45 seconds, they go back and forth in their negotiation with Linda using AI-generated responses. At 0.34 seconds, Teagan explains the person they are planning the party for has “…a lot of friends and a pretty big family…so that number of people is not unreasonable.” Linda follows at 0.48 seconds with a Move hedge, “I don’t know.” At 0.53 seconds, Teagan asks a very specific question: “Why don’t you want to invite that many people?” At 1 minute, Linda begins constructing her specific answer on the QWERTY keyboard, which takes 2 minutes 45 seconds, and says, “It’s harder to keep it a surprise.”
Theme 3: Relevance Must Include Role, Stance, Goal, and Personal Voice
Todd and Linda both made clear that “relevant” AI output is not enough. A response can fit the topic and still fail the user. Todd laughed at some AI responses because they made sense in the situation, but they were not things he would have said. This distinction is important: DEAN sometimes spoke on Todd’s behalf without speaking “as Todd”.
For Todd, the next version of DEAN needs stronger modeling of role, goal, stance, persona, and conversational partner. In the role-play scenarios, he needed responses that aligned with his assigned role, intended strategy, and preferred interpersonal style. He also raised the possibility that the system should know who he is talking to and adapt based on the relationship and prior interaction history.
Linda’s comments point to the same issue. When the scenario required objection, the system needed to support objection. When the task required negotiation, the system needed to support negotiation. The relevant unit was not just the partner’s previous utterance; it was the participant’s role in the scene, her stance toward the partner’s proposal, and the direction she wanted the interaction to take.
The design conclusion is direct: In addition to meeting the user’s communication goals in conversation, conversational AI should generate user-authorized options that fit the user’s role, stance, action project, and communicative identity.
This short sequence demonstrates how some AI responses can be topically relevant, but not meet the user’s goals in the conversation and some are just off topic. Things start off well, then at 0.18 seconds, Kendra asks Todd what else he likes about Florida, to which he replies, “Love water. It’s calming”, at 0.22 seconds. Kendra agrees that she also loves water but, at 0.28 seconds, points out, “There’s water elsewhere.” Todd spends about 10 seconds considering AI-predicted responses, then immediately interjects after Kendra’s turn at 0.42, saying, “Buffalo’s water is the best.” They both laugh at this comment because it is clear from when Buffalo water came up earlier that neither of them has high regard for Buffalo’s beaches. As Todd mentioned in the debrief, he sometimes chooses a response just to move the conversation along and not because it best represents his point of view. He also laughed when he spoke it, suggesting it should perhaps be taken as a joke. Kendra laughs, suggesting she knows Todd is joking, then indicates she disagrees at 46 seconds. At this point, apparently continuing to joke, Todd chooses a wildly off-topic response, “I love hotwings,” at 50 seconds and both continue to look at one another and laugh. Although both Todd and Kendra seemed to enjoy the joking, Todd’s frustration during the debriefing interviews, as AI predictions did not reflect his stance, is clearly evident in this segment.
Theme 4: Personal AAC Systems Remained Central to Authorship
Both participants found useful features in DEAN, but neither treated it as a replacement for their personal AAC system. Todd continued to prefer Minspeak because it is his established language system. It gives him access to words through familiar symbol sequences, reduces spelling burden, and reflects decades of practice. His critique of DEAN was not just that it made errors. It lacked his word system and sometimes produced messages that did not sound like him.
Linda’s Dynavox remained essential for a different reason. It supported precisely authored expression. DEAN could help her engage in the interaction, but when she needed specific details, nuanced explanations, or fully authored turns, she still relied on typing either via the QWERTY keyboard in DEAN-mediated interactions or on her personal Dynavox device. The problem was not authorship.
These findings suggest that continued development of AI-enhanced AAC applications should work as a support layer coordinated with the user’s personal AAC system or analogous features. For augmented communicators like Todd who use Minspeak or other word-based systems, this suggests integrating AI as an adjunct to their current AAC language system. Additionally, support for reading AI-generated messages, such as wireless earbuds, may be needed to reduce the cognitive burden of reviewing and selecting messages for people like Todd who are not proficient in reading. For highly literate users like Linda, these points toward AI-enhanced systems that provide turn-entry, stance-marking, and floor-holding support that works alongside keyboard-based authored message construction with spelling and word prediction. For both types of augmented communicators, as AI improves, there is potential to build in more of their desired capabilities, making the application of AI in AAC technology an evolving process.
Theme 5: Partner Engagement Increased When Participation Became Visible or Audible
Todd’s stimulated recall interviews revealed something especially important. When using DEAN (Moves or AI-predicted responses), he felt like he was “talking” and noticed that Kendra was listening more attentively. This appeared to be due to the immediacy of his contributions compared with composing messages with his Minspeak system. After using DEAN on the first day of the study, he changed his own Minspeak output mode so that words were spoken as he composed them. This suggests that using DEAN helped him see the value of making message construction more visible or audible to the partner.
This observation connects directly with the broader findings from Project Engage. Partner engagement increases when the communication partner has more frequent access to the message as it is being constructed. Todd seemed to recognize this in practice. Word-by-word output made his participation feel more immediate and harder for the partner to drift away.
But, for Todd, this came at a cost. Word-by-word output made the errors public immediately. If he selected the wrong item, he spoke the wrong word before he could correct it. So incremental output can increase engagement but also increase risk. It lowers the boundary between composing and publicly saying.
Linda’s account raised a parallel issue. If she is composing silently, partners may move on. But if she must constantly monitor AI options, she may lose eye contact and social contact. Dean, therefore, needs to support partner engagement without overloading the augmented speaker’s visual attention or exposing unintended output.
The broader design need is configurable publicness. Users should be able to decide when composition remains private, when partial output becomes visible or audible, when a floor-holding signal is produced, and when a message is formally spoken.
Theme 6: The Most Important Design Direction Is User-Controlled Integration
The next version of DEAN should be designed as a user-controlled conversational support layer, not as an autonomous message generator. Its job should be to help with timing, stance, word retrieval, spelling burden, partner orientation, and sequential placement while preserving the user’s authority over what is said.
Next iterations of AI-enhanced AAC for users like Todd, should consider a parallel Minspeak + AI model. Todd imagined AI operating alongside his own system so that he could begin from a familiar Minspeak organization and then receive AI-supported information or alternatives after he initiates a direction. For users like Linda, the strongest direction might be a sequential AI-plus-spelling-and-word-prediction model. This could help her enter the interaction quickly, hold the floor, and mark the relevant prior turn. Spelling and word prediction, as available on her Dynavox, would remain essential for fuller authored expression, but it should also be able to direct AI responses with short prompts related to the user’s goal in the conversation.
All of this makes clear that a single conversational AI architecture will not meet the needs of the wide variety of AAC users. The focus should be on making systems configurable around the user’s existing AAC ecology.
The qualitative data show that DEAN can support conversational engagement by helping augmented speakers align with the conversation’s timing. DEAN worked best when it helped the participant enter the interaction quickly, keep the partner oriented, and reduce the burden of composing every contribution from scratch. But speed and relevance were not enough. AI-generated messages had to support the augmented speaker’s intended stance, role, goal, and personal voice.
Todd and Linda’s feedback makes one point especially clear: AI-enhanced AAC should not be understood as a system that talks for the user. It should be understood as a system that helps the user participate in the temporal, sequential, and social organization of conversation.
The next stage of DEAN development should focus on integration with personal AAC systems, user-controlled stance and goal settings, floor-holding tools, save/resume functions, repeat options, configurable public output, and conversational partner/persona memory. DEAN’s future value lies in helping AAC users stay on time without losing agency or authorship.